
使用KVectors向量数据库构建以图搜图应用
王福强
以图搜图是电商平台上很常见的用户需求,
今天,我们尝试用最轻量级的方式,
为大家演示如何用KVector向量数据库构建一个以图搜图应用。
KVectors 支持三层访问模式:
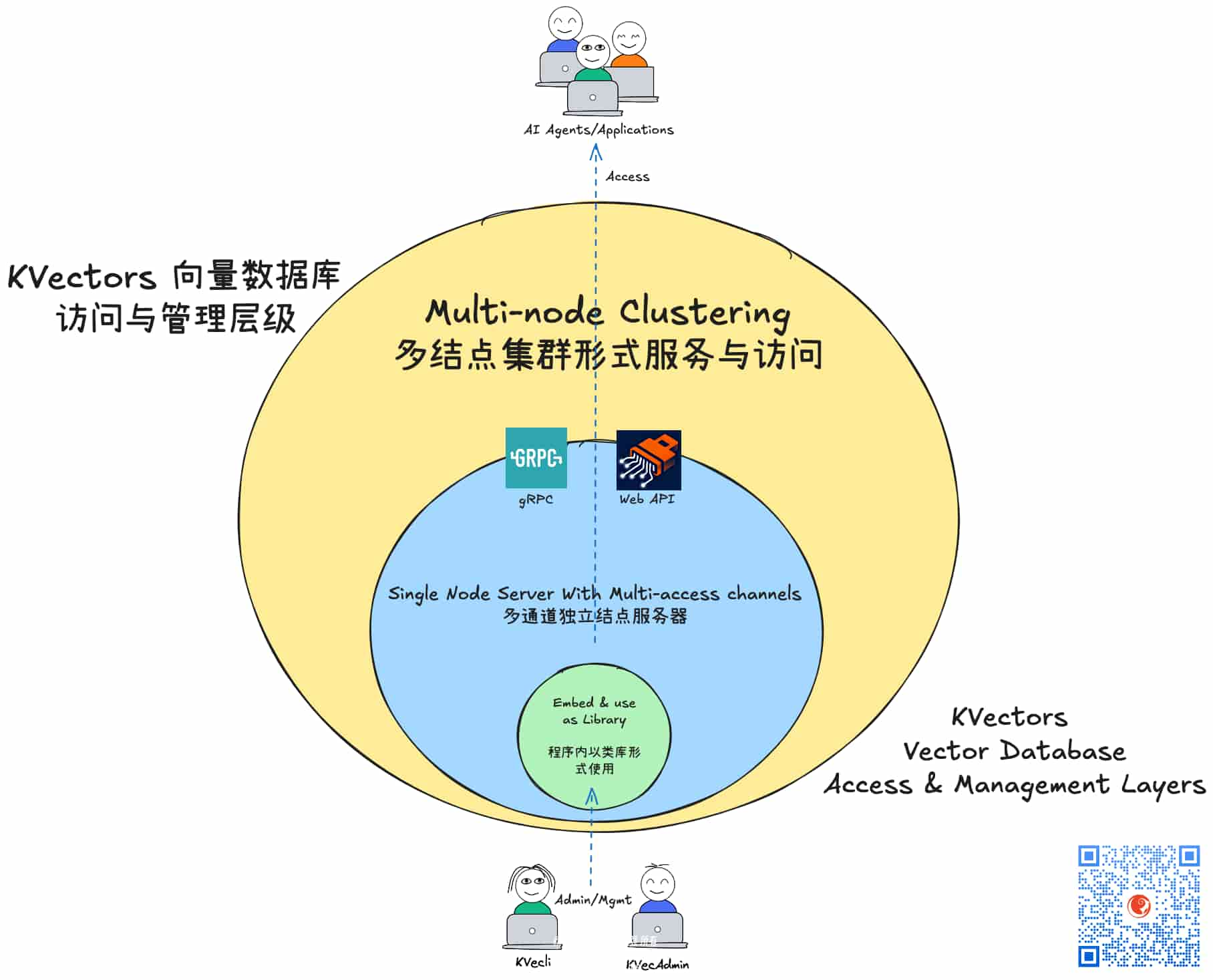
我们选择最内核的方式,即以Library/类库的方式使用KVectors,因为这可以帮助我们构建最内聚的应用集成度, 安装与部署和使用对用户来说都更为友好。
整个以图搜图的应用流程很简单,主要两个方向:
- 上传图片到图片存储到时候(比如云上的对象存储,或者其他第三方图床), 我们会使用图像Embedding模型对上传的图片进行embedding操作, 然后将获得的图片对应的embedding(即向量)存入KVectors向量数据库。 当然,图片的上传与计算图像Embedding可以是并行的(也可以串行),这个根据应用的时延(Latency)要求决定就可以了。
- 搜索图像的时候,用户提交一个图像,我们依然是先针对这个图像进行Embedding,获得对应的embedding向量之后,拿着它去KVectors向量数据库中去搜索相似的embeddings,然后将相似的embeddings作为搜索结果,并根据其对应的元信息(metadata)获取对应的原始图像信息(比如存储地址),然后再展示给用户,从而完成整体的以图搜图闭环功能。
既然本次我们主要专注在轻量与集成度上,图像的embedding模型我们选择了一个比较老的小模型:MobileNetV2,相对于最新的VL模型或者CLIP模型,效果上可能不是最好的,但完成基础的以图搜图能力还是没有问题的(无非搜索的时候threshold要降低下标准🤪)
图像embedding与存入KVectors的代码大体如下:
public float[] embed(String imagePath) throws IOException, OrtException {
float[] preprocessedData = MobileNetV2ImagePreprocessor.preprocessImage(imagePath);
long[] inputShape = {1, 3, 224, 224};
OnnxTensor inputTensor = OnnxTensor.createTensor(environment, FloatBuffer.wrap(preprocessedData), inputShape);
try (OrtSession.Result result = session.run(Collections.singletonMap("pixel_values", inputTensor))) {
return ImageEmbeddingExtractor.extractWithGlobalAvgPooling(result);
}
} val collectionOption = kdb.getCollection("ImageSearchVectorCollectionName")
if (collectionOption.isDefined) {
val vectorCollection = collectionOption.get
vectorCollection.add(VectorRecord(vector, VectorMetadata(url, None)))
} else {
throw new IllegalStateException(s"no vector collection found in kvectors db at ${kdb.dataDir}")
}kdb即KVectors向量数据库的对象引用,它的初始化也很简单:
val kdb = new KVectors(new File(keeboxDir, "kvectors")) // <<< 主要这一行
Shutdowns.addShutdownRunnable(() => Cleaner.closeWithLog(kdb)) // 这行是为了擦屁股,在程序关闭后清理KVectors的相应资源KVectors的设计包含向量数据库和向量集合(KVectorCollection)两级概念,一个KVectors向量数据库可以包含很多向量集合(KVectorCollection), 向量最终存入相应的向量集合(KVectorCollection),比如上面是用一个假名字ImageSearchVectorCollectionName作为向量集合的名字(这个参数你可以根据情况取)获得对应的向量集合对象引用,然后向其中添加向量。(向量集合预先已经在其他地方创建)
最后就是, VectorRecord的第一个参数vector就是前面embed方法返回的结果。 至于文件上传的代码,就不演示了,根据选用的公有云不同而API不同。
当图像的embedding存入KVectors向量数据库之后, 我们就可以针对他们进行相似度搜索了,来了一个图像,我们依然对其进行embed调用获得图像对应的embedding向量, 然后根据获得的这个embedding向量到KVectors向量数据库中查询:
val embeddingVector = imageEmbeddingExecutor.embed(tmpFile.getAbsolutePath)
val collectionOption = kdb.getCollection("ImageSearchVectorCollectionName")
if (collectionOption.isDefined) {
val ab = new ArrayBuffer[SearchResult]()
logger.info(s"start search with topK=${topK}, threshold=${threshold} ..")
collectionOption.get.query(embeddingVector, topK = topK, threshold = threshold).forEach(vectorResult => {
val score = vectorResult.score.get
val url = vectorResult.meta.getString("rid")
logger.info(s"found image meet threshold at ${url} with score=${score}")
ab.append(SearchResult(url, score))
})
ab.toArray
} else {
Array.empty
}KVectors的设计中要求每个向量存入之前都要有一个 relation id 与之对应,在以图搜图这个场景中,我们使用图像的url作为这个relation id,即meta元信息中的rid的值就是图像的url, 这个值我们将用来获取图像展示给用户。(同时,用户点击图像的时候,会打开对应图像)
搜索的时候,除了图像的embedding向量, 还有两个参数要跟大家说明下:
- topK,这个参数主要控制搜索结果的数量,比如返回11条相似性结果或者50条,这个根据应用需求决定就好了;
- threshold, 这个参数控制相似性匹配的标准,取值一般在0到1之间,假如Embedding模型质量很好,一般设置0.8以上就可以了,我们选择的 MobileNetV2 模型因为年代久远而且参数量比较少,有些时候效果不理想,所以,偶尔需要降低threshold的值,比如降低到0.6,0.7这样。
下面是以图搜图的一个JavaFX应用的简单界面,供大家参考视觉效果:
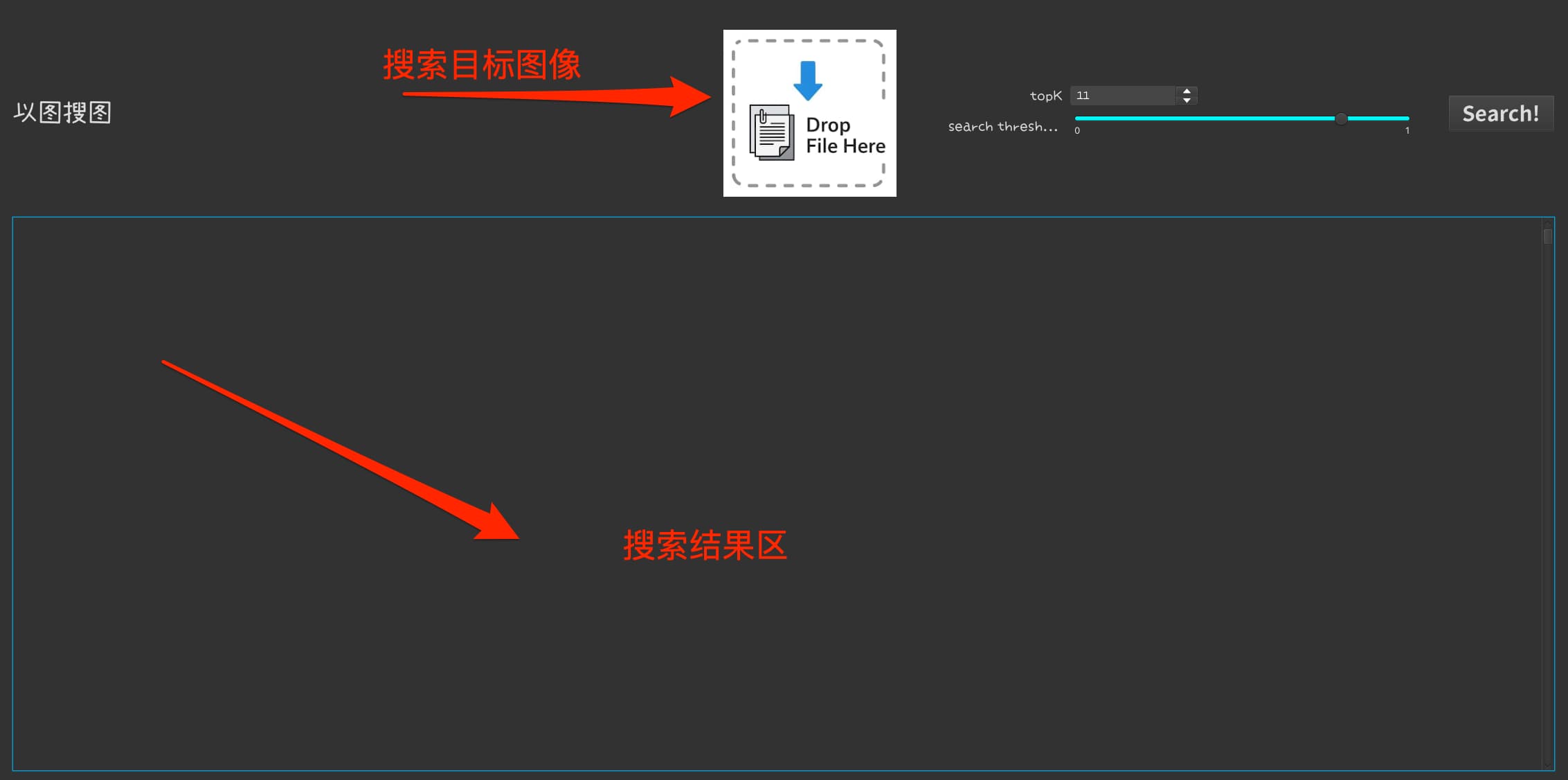
用户通过拖拽或者剪切板粘贴要搜索的图像到目标区域(即Drop File Here图标位置),点击Search就可以获得搜索结果了。
当然,点击搜索之前,也可以调整topK和threshold两个参数的默认值。
至此,一个基于KVectors向量数据库的以图搜图应用就算构建完成了,是不是很简单?
除了以图搜图场景,KVectors向量数据库还可以在产品推荐、客服知识库、传统与各种RAG变种等不同场景发挥同样强大的作用。
海量向量数据集中搜索时延 6.8 毫秒,可不是谁家的向量数据库都能达到的指标哟 🤪
同时欢迎各大企业预定与选购KVectors向量数据库,让自己在AI时代划出美丽的第二增长曲线。😎


开天窗,拉认知,订阅「福报」,即刻拥有自己的全模态人工智能。
