Table of Contents
CobarClient主要针对现有网站应用中使用iBatis做数据访问层这一情况而设计开发,如果你的应用程序最初使用了Spring提供的SqlMapClientTemplate的话, 那迁移到CobarClient实际上仅仅是稍微改一下应用程序的配置而已.
假设原有的应用程序依赖于Spring的SqlMapClientTemplate进行数据访问, 那么, 使用Cobar Client之后, 只要修改配置, 让应用程序依赖于CobarClient的CobarSqlMapClientTemplate即可. 同时, 与数据访问相关的事务管理也需要从使用Spring原生的DataSourceTransactionManager, 换为CobarClient提供的MultipleDataSourcesTransactionManager, 整个迁移的概况类似于:
使用CobarClient之前: <bean id="sqlMapClientTemplate" class="org.springframework.orm.ibatis.SqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient"/> ... </bean> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource"/> ... </bean> <bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="configLocation" value="classpath:META-INF/ibatis/sqlmap-config.xml" /> </bean> <bean id="dataSource" ...> ... </bean>
使用CobarClient之后: <bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient"/> ... </bean> <bean id="transactionManager" class="com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager"> ... </bean> <bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="configLocation" value="classpath:META-INF/ibatis/sqlmap-config.xml" /> </bean> <bean id="dataSource" ...> ... </bean>
可见, 基本上只需要替换两处配置即可完成迁移工作.
不过, 以上只是简化后的迁移场景, 实际上, 还有一些细节需要我们完善之后, 才能完全的完成整个的迁移工作.
在单数据源的情况下, SqlMapClientTemplate(或者说它依赖的SqlMapClient)以及对应进行事务管理的DataSourceTransactionManager都会引用同一个数据源; 而当应用进行数据拆分之后, 物理上将对应多个数据源, 要进行数据访问和事务管理, 我们现在必须针对数据拆分之后对应的多个数据源进行.为了同一的管理这种依赖, CobarClient提供了ICobarDataSourceService这一抽象接口用于归类管理数据拆分后对应的多个数据源, com.alibaba.cobar.client.CobarSqlMapClientTemplate和com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager现在将都依赖于某个ICobarDataSourceService的实现来提供对某些数据源的依赖, 这样, 最初的配置将演化为如下的形式:
<bean id="dataSources" class="某个ICobarDataSourceService实现类"> ... </bean> <bean id="transactionManager" class="com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager"> <property name="cobarDataSourceService" ref="dataSources" /> </bean> <bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> ... </bean> <bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="configLocation" value="classpath:META-INF/ibatis/sqlmap-config.xml" /> </bean>
也就是说, 现在MultipleDataSourcesTransactionManager和CobarSqlMapClientTemplate都有一个cobarDataSourceService依赖, 该依赖都将引用同一个bean定义dataSources(注意这里的名称为复数). 该bean定义将对应某个ICobarDataSourceService实现类, 当前, 我们提供了com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService作为ICobarDataSourceService的默认实现, 其常见配置如下:
<bean id="dataSources" class="com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService"> <property name="dataSourceDescriptors"> <set> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition1"/> <property name="targetDataSource" ref="partition1_main"/> <property name="targetDetectorDataSource" ref="partition1_main"/> <property name="standbyDataSource" ref="partition1_standby"/> <property name="standbyDetectorDataSource" ref="partition1_standby"/> </bean> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition2"/> <property name="targetDataSource" ref="partition2_main"/> <property name="targetDetectorDataSource" ref="partition2_main"/> <property name="standbyDataSource" ref="partition2_standby"/> <property name="standbyDetectorDataSource" ref="partition2_standby"/> </bean> </set> </property> <property name="haDataSourceCreator"> <bean class="com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator"> <property name="detectingSql" value="update cobarha set timeflag=CURRENT_TIMESTAMP()"/> </bean> </property> </bean> <bean id="partition1_main" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="org.h2.Driver" /> <property name="jdbcUrl" value="jdbc:h2:mem:p1_main;DB_CLOSE_DELAY=-1;MODE=MySQL;LOCK_MODE=3" /> <property name="user" value="" /> <property name="password" value="" /> <property name="minPoolSize" value="10" /> <property name="maxPoolSize" value="20" /> <property name="maxIdleTime" value="1800" /> <property name="acquireIncrement" value="2" /> <property name="maxStatements" value="0" /> <property name="initialPoolSize" value="2" /> <property name="idleConnectionTestPeriod" value="1800" /> <property name="acquireRetryAttempts" value="30" /> <property name="breakAfterAcquireFailure" value="true" /> <property name="testConnectionOnCheckout" value="false" /> </bean> <bean id="partition1_standby" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="org.h2.Driver" /> <property name="jdbcUrl" value="jdbc:h2:mem:p1_standby;DB_CLOSE_DELAY=-1;MODE=MySQL;LOCK_MODE=3" /> <property name="user" value="" /> <property name="password" value="" /> <property name="minPoolSize" value="10" /> <property name="maxPoolSize" value="20" /> <property name="maxIdleTime" value="1800" /> <property name="acquireIncrement" value="2" /> <property name="maxStatements" value="0" /> <property name="initialPoolSize" value="2" /> <property name="idleConnectionTestPeriod" value="1800" /> <property name="acquireRetryAttempts" value="30" /> <property name="breakAfterAcquireFailure" value="true" /> <property name="testConnectionOnCheckout" value="false" /> </bean> <bean id="partition2_main" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="org.h2.Driver" /> <property name="jdbcUrl" value="jdbc:h2:mem:p2_main;DB_CLOSE_DELAY=-1;MODE=MySQL;LOCK_MODE=3" /> <property name="user" value="" /> <property name="password" value="" /> <property name="minPoolSize" value="10" /> <property name="maxPoolSize" value="20" /> <property name="maxIdleTime" value="1800" /> <property name="acquireIncrement" value="2" /> <property name="maxStatements" value="0" /> <property name="initialPoolSize" value="2" /> <property name="idleConnectionTestPeriod" value="1800" /> <property name="acquireRetryAttempts" value="30" /> <property name="breakAfterAcquireFailure" value="true" /> <property name="testConnectionOnCheckout" value="false" /> </bean> <bean id="partition2_standby" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="org.h2.Driver" /> <property name="jdbcUrl" value="jdbc:h2:mem:p2_standby;DB_CLOSE_DELAY=-1;MODE=MySQL;LOCK_MODE=3" /> <property name="user" value="" /> <property name="password" value="" /> <property name="minPoolSize" value="10" /> <property name="maxPoolSize" value="20" /> <property name="maxIdleTime" value="1800" /> <property name="acquireIncrement" value="2" /> <property name="maxStatements" value="0" /> <property name="initialPoolSize" value="2" /> <property name="idleConnectionTestPeriod" value="1800" /> <property name="acquireRetryAttempts" value="30" /> <property name="breakAfterAcquireFailure" value="true" /> <property name="testConnectionOnCheckout" value="false" /> </bean>
DefaultCobarDataSourceService引用一组com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor, 每一个com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor 描述了针对某一数据拆分分区的必要依赖, 这包括:
identity. 数据分区的唯一标志, 该标志不可与其它数据分区的标志冲突, 在定义路由规则的时候, 数据分区标志将成为路由规则的一部分.
targetDataSource. 主要目标数据源的依赖引用, 通常意义上, 应用启动的时候该数据源必须是Active的.
targetDetectorDataSource. 主要目标数据源伴随的HA探测用数据源, 主要用于检测主要目标数据源的状态, 通常指向与主要目标数据源相同的目标数据库, 但数据库连接池要单独配置, 以防止相互干扰.
standbyDataSource. 与主要目标数据源并列的备用数据源, 当主要目标数据源出现问题之后, 如果启用了CobarClient的HA功能支持, CobarClient将自动将数据访问切换到该备用数据源上.
standbyDetectorDataSource. 备用数据源对应的HA探测用数据源.
Note
因为当前网站的数据源配置都是通过JNDI进行, CobarClient无法统一取得数据库连接等相关信息, 也就无法根据同一份配置信息自行创建相应的数据库连接池, 所以, 只好需要应用程序方针对每一个目标数据源再多配置一个用于HA状态探测用的数据源引用.
当前CobarDataSourceDescriptor之所以需要这些信息是因为现在网站最主要的数据库部署结构是HA双机热备的水平切分数据库集群, 但后期如果有其它的数据库部署结构, CobarDataSourceDescriptor也可能随着数据库部署结构的调整而调整.
Tip
如果不需要HA双机热备支持, 那么可以让standby(.*)DataSource指向target(.*)DataSource相同的数据源应用, 或者如果DefaultCobarDataSourceService的haDataSourceCreator没有指定的话, standbyDataSource,standbyDetectorDataSource和targetDetectorDataSource可以完全不配置.
CobarDataSourceDescriptor引用的数据源可以来自JNDI绑定的数据源, 也可以来自容器内定义的数据源(如上配置所示, 为了测试,我们使用了Spring容器内定义的C3P0数据源), 甚至其它形式提供的数据源, 只要为其提供标准的JDBC API中的DataSource接口实现即可.
DefaultCobarDataSourceService除了依赖一组CobarDataSourceDescriptor, 它还依赖于相应的IHADataSourceCreator来进行数据库的HA支持, 如果没有提供相应的IHADataSourceCreator实现类, DefaultCobarDataSourceService默认会使用NonHADataSourceCreator, 即不创建支持HA的数据源. CobarClient默认提供了FailoverHotSwapDataSourceCreator以支持HA, 应用方可以根据情况提供自己的IHADataSourceCreator实现来满足特定场景需要.
有关数据切分分区多数据源管理相关的迁移说明就说到这里, 下面我们来进一步看一下其它相关配置细节.
因为com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager属于标准的Spring的PlatformTransactionManager实现, 除了唯一特定于CobarClient的ICobarDataSourceService依赖之外, 其它都继承自Spring标准类AbstractPlatformTransactionManager, 故此其配置在这里就不做更多说明了,应用方可以参阅Spring的相关文档获取更多配置和使用信息. 下面我们主要针对CobarSqlMapClientTemplate的相关依赖进行进一步说明.
CobarSqlMapClientTemplate依赖某个ICobarDataSourceService实现类来获取数据拆分分区相关信息, 为了将相应的数据访问请求路由到相应的数据分区, 它也需要依赖于一个ICobarRouter实现类以决定如何进行数据访问请求的路由. 所以, 一个功能完备的CobarSqlMapClientTemplate配置应该如下所示:
<bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> <property name="router" ref="internalRouter" /> <property name="sqlAuditor"> <bean class="com.alibaba.cobar.client.audit.SimpleSqlAuditor" /> </property> <property name="profileLongTimeRunningSql" value="true" /> <property name="longTimeRunningSqlIntervalThreshold" value="3600000" /> </bean> <bean id="internalRouter" class="com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean"> <property name="functionsMap"> <map> <entry key="mod"> <bean class="com.alibaba.cobar.client.router.rules.support.ModFunction"> <constructor-arg><value>128</value></constructor-arg> </bean> </entry> </map> </property> <property name="configLocations"> <list> <value>classpath:META-INF/routing/offer-sql-action-rules.xml</value> <value>classpath:META-INF/routing/offer-sharding-rules-on-namespace.xml</value> </list> </property> </bean>
Note
关于sqlAuditor, profileLongTimeRunningSql, longTimeRunningSqlIntervalThreshold等配置项, 可以参考CobarClient Reference文档, 他们是可选的, 所以这里不做更多说明.
Cobar Client默认提供的ICobarRouter实现类是com.alibaba.cobar.client.router.CobarClientInternalRouter, 为了简化配置, 我们为其提供了一个FactoryBean用于简化配置, 即com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean, 其中最主要的配置项为configLocations(或者configLocation, 如果只需要指定一个路由规则说明文件的话), 该配置项主要用于指定路由规则说明文件所在的位置, com.alibaba.cobar.client.router.CobarClientInternalRouter将根据这些路由规则说明文件中的路由规则进行数据访问请求的路由. 下面是一个典型的路由规则说明文件实例:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>mod.apply(memberId)==1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>mod.apply(memberId)==2</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
如果我们注意到在配置com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean的时候,我们通过functionsMap属性指定了一个自定义函数Map的话, 那么,在路由规则的shardingExpression中, 就不难发现该自定义函数的身影了.
因为以上路由规则定义很简单,所以我们没有强制要求使用DTD或者XML Schema,但实际上, 路由规则的DTD可以简单描述如下:
<?xml version="1.0"? encoding="UTF-8"?> <!ELEMENT rules (rule)+> <!ELEMENT rule ((namespace|sqlmap),shardingExpression,shards)> <!ELEMENT namespace (#PCDATA)> <!ELEMENT sqlmap (#PCDATA)> <!ELEMENT shardingExpression (#PCDATA)> <!ELEMENT shards (#PCDATA)>
路由规则在当前的CobarClient中分为四种类型, 详情参见CobarClient Reference文档. 总之, 有了以上配置之后, 你就可以开始使用Cobar Client进行数据切分集群下的数据访问之旅了.
现有的Cobar方案需要单独的服务器来运行, 为了保证性能和可用性, 通常最少需要两台独立服务器.国际站应用方出于扩展和可用性等因素考虑, 希望一种不依赖于独立服务器的Cobar解决方案, 鉴于此, 决定开发Cobar的Client版本, 该版本主要面向小规模的数据库sharding集群访问, 因现有的Cobar已经在中文站等多个项目中成功应用并实施, 如果CobarClient无法满足进一步的需求,可以转而使用现有的Cobar方案.
所以, CobarClient的使用原则上只限定于某些特定场景.
CobarClient需要满足以下需求:
可以支持垂直和水平数据切分数据库集群的访问;
支持双机热备的HA解决方案, 应用方可以根据情况选用数据库特定的HA解决方案(比如Oracle的RAC),或者选用CobarClient提供的HA解决方案.
小数据量的数据集计(Aggregation), 暂时只支持简单的数据合并.
数据库本地事务的支持, 目前采用Best Efforts 1PC模式的事务管理.
数据访问操作相关SQL的记录, 分析等.(可以采用国际站现有Ark解决方案,但CobarClient提供扩展的切入接口)
CobarClient的实现方案可以从多个角度进行考虑, 我们暂且选择三种方案进行推演.
因为现有的Cobar解决方案通过SQL解析来实现了shards间的路由功能, 所以, 自然而然的, 大家会马上联想到在JDBC Driver层次进行同样的封装,然后也是通过SQL解析的方式来实现路由功能. 首先这种方案是可以实现的, 但工期也绝对不会像想象的那么短.
要走这条路, 我们不可能通过封装或者拦截几个JDBC接口就很容易的搞定, 我们需要实现一整套的JDBC规范,这无论从开发还是测试方面考虑,投入的时间都会很多.
最初我们尝试只拦截Connection, Statement的相关方法来获取SQL并进行解析等工作,但发现相关方法调用的lifecycle的不匹配问题, 方法调用的trace问题, 数据库metadata等都会造成实现过程中的“尴尬”和难行.
但不管怎么样, 完全的实现一套JDBC规范的API,原则上来说可以实现类似于现有Cobar解决方案类似的方案.
要实现数据方案的路由功能, 我们也可以在数据访问层做文章. 从DAL层做文章的好处在于, 我们可以规范开发流程, 简化路由功能的实现, 而且, 不管将来增加更多的shards或者其它异构的存储, 比如KV store, DAL层都可以屏蔽这些变化, 使得应用程序不受任何影响.
如果采用DAL层的解决方案, 我们可以将sharding策略和规则“外部化”, 通过统一的配置(Annotation也好, 外部XML之类配置文件也好)来定义路由规则, 路由规则可以根据DO的类型以及相关属性进行定义, 定义简单又不失灵活性, 完全不用引入SQL解析之类的复杂性.
但基于DAL层次的解决方案对现有网站的应用来说, 冲击性太大,所以, 这虽然是个方向,但短期内无法有效施行.
考虑到工期以及兼容性等因素, 我们可以考虑介于JDBC API层次的解决方案和DAL层次的解决方案之间的一种解决方案.
B2B内部数据访问全部采用iBatis进行, 为了提高开发效率,自然也采用了Spring提供的SqlMapClientTemplate进行数据访问逻辑的开发. 要较少的侵入现有应用, 我们可以考虑对SqlMapClientTemplate做手脚, 既然所有的数据访问都通过该类走,那么就在该类中插入路由逻辑, 根据数据访问请求的属性指定路由规则, 然后将符合路由规则的数据访问请求路由到相应的shard上去.
这实际上就是我们现在第一阶段采用的解决方案.
CobarClient现有方案的架构如下图所示:
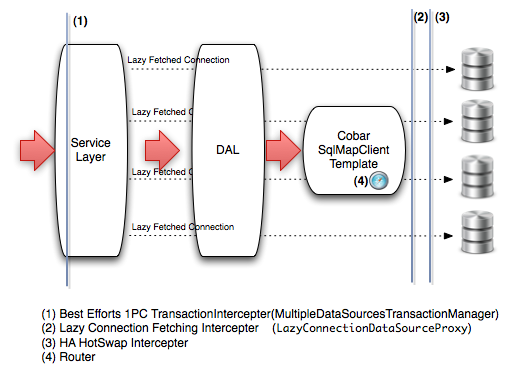
架构中主要侧重解决两个方面的问题:
数据访问请求的路由. 通过扩展Spring提供的SqlMapClientTemplate来切入进行扩展, 我们提供了自定义的CobarSqlMapClientTemplate, 并结合相应的Router支持来实现数据访问请求的路由功能, 并且尽量保持现有应用代码的兼容. 应用的迁移工作基本上只要替换注入的SqlMapClientTemplate实现类即可.
多数据源访问过程中的事务管理. 因为两阶段提交的分布式事务会严重影响应用的性能, 所以, 根据网站方需求,我们退而求其次, 采用Best Effort 1PC Pattern的事务策略, 提供了基于该Pattern的一个事务管理器实现MultipleDataSourcesTransactionManager, 该事务管理器扩展自Spring的AbstractPlatformTransactionManager, 应用程序迁移的时候只需要替换使用的事务管理器实现类即可.该事务管理器实现最大程度上保证事务管理的性能损失与数据一致性之间的一个合理权衡.
另外, 我们也通过AOP实现了数据源之间的HA,以及延迟加载数据库连接以保证资源的有效使用等功能, 这些在以上架构图中都有所体现.
鉴于CobarClient的两个主要关注点, 我们将对这两个关注点对于的主要组件进行详细的说明, 下面是详细内容, 各位看官上眼了...
CobarSqlMapClientTemplate扩展了Spring的SqlMapClientTemplate, 主要在SqlMapClientTemplate的基础之上添加了数据访问请求的路由功能, 以便应用程序可以透明的访问数据库切分后的各个数据库节点. 除此之外, CobarSqlMapClientTemplate也提供了一些附加的功能, 以方便应用的监控和使用. 下面我们分部分阐述CobarSqlMapClientTemplate的相关功能.
在没有进行数据库切分之前, 应用程序使用Spring的SqlMapClientTemplate进行数据访问只需要为其提供单一的数据源引用, 类似于:
<bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> ... </bean>
进行数据切分之后, 因为数据访问可能加诸在不同的数据切分分区上, 也就是说, 需要同时引用多个数据源依赖, 所以, 我们需要通过某种方式来管理这多个数据源的依赖, 并将其注入给CobarSqlMapClientTemplate使用. 在Cobar Client中, 完成这一工作的是ICobarDataSourceService抽象:
public interface ICobarDataSourceService {
Map<String, DataSource> getDataSources();
Set<CobarDataSourceDescriptor> getDataSourceDescriptors();
}
ICobarDataSourceService将负责为CobarSqlMapClientTemplate提供一组依赖的数据源, 并且在必要的情况下, 提供各个数据源相关的元数据信息. ICobarDataSourceService有一默认实现类,即com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService, 通过DefaultCobarDataSourceService, 我们可以集中管理各个数据源, 并将他们注入给CobarSqlMapClientTemplate使用. 常见的CobarSqlMapClientTemplate和其ICobarDataSourceService依赖的配置情况如下所示:
<bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> ... </bean> <bean id="dataSources" class="com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService"> <property name="dataSourceDescriptors"> <set> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition1"/> <property name="targetDataSource" ref="partition1_main"/> <property name="targetDetectorDataSource" ref="partition1_main"/> <property name="standbyDataSource" ref="partition1_standby"/> <property name="standbyDetectorDataSource" ref="partition1_standby"/> <property name="poolSize" value="10"/> </bean> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition2"/> <property name="targetDataSource" ref="partition2_main"/> <property name="targetDetectorDataSource" ref="partition2_main"/> <property name="standbyDataSource" ref="partition2_standby"/> <property name="standbyDetectorDataSource" ref="partition2_standby"/> </bean> </set> </property> <property name="haDataSourceCreator"> <bean class="com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator"> <property name="detectingSql" value="update cobarha set timeflag=CURRENT_TIMESTAMP()"/> </bean> </property> </bean> <bean id="partition1_main" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> ... </bean> <bean id="partition1_standby" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> ... </bean> <bean id="partition2_main" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> ... </bean> <bean id="partition2_standby" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> ... </bean>
注意, CobarSqlMapClientTemplate依然需要一个iBatis的SqlMapClient的引用, 因为CobarSqlMapClientTemplate依然是一个SqlMapClientTemplate(虽然听起来有些废话). 以上配置中重头戏在于com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService的配置, 我们需要通过 “dataSourceDescriptors” 属性, 为其注入一组com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor, CobarDataSourceDescriptor主要负责对相应的数据源进行描述, 其主要配置信息包括:
identity. 数据分区的唯一标志, 该标志不可与其它数据分区的标志冲突, 在定义路由规则的时候, 数据分区标志将成为路由规则的一部分.
targetDataSource. 主要目标数据源的依赖引用, 通常意义上, 应用启动的时候该数据源必须是Active的.
targetDetectorDataSource. 主要目标数据源伴随的HA探测用数据源, 主要用于检测主要目标数据源的状态, 通常指向与主要目标数据源相同的目标数据库, 但数据库连接池要单独配置, 以防止相互干扰.(以上配置中引用了同一个数据源引用, 只是为了演示的方便)
standbyDataSource. 与主要目标数据源并列的备用数据源, 当主要目标数据源出现问题之后, 如果启用了CobarClient的HA功能支持, CobarClient将自动将数据访问切换到该备用数据源上.
standbyDetectorDataSource. 备用数据源对应的HA探测用数据源, 存在的目的参见targetDetectorDataSource的说明.
poolSize. CobarSqlMapClientTemplate需要根据每个目标数据源的数据库连接的数量来创建相应的线程池以便提高并发处理性能, poolSize可以帮助CobarSqlMapClientTemplate决定创建的线程池的大小,如果配置的时候该项不做配置的话, 默认情况下将以CPU内核的数量乘以5作为默认大小.
Note
因为当前网站的数据源配置都是通过JNDI进行, CobarClient无法统一取得数据库连接等相关信息, 也就无法根据同一份配置信息自行创建相应的数据库连接池, 所以, 只好需要应用程序方针对每一个目标数据源再多配置一个用于HA状态探测用的数据源引用.
配置实例中使用了C3P0作为容器内的数据源定义, 但CobarClient只依赖标准的DataSource接口, 所以并不止限于C3P0数据源类型, JNDI查找的数据源或者DBCP, 甚至自己实现的DataSource都是可以的.
当前CobarDataSourceDescriptor之所以需要这些信息是因为现在网站最主要的数据库部署结构是HA双机热备的水平切分数据库集群, 但后期如果有其它的数据库部署结构, CobarDataSourceDescriptor也可能随着数据库部署结构的调整而调整.
Tip
如果不需要HA双机热备支持, 那么可以让standby(.*)DataSource指向target(.*)DataSource相同的数据源应用, 或者如果DefaultCobarDataSourceService的haDataSourceCreator没有指定的话, standbyDataSource,standbyDetectorDataSource和targetDetectorDataSource可以完全不配置.
CobarDataSourceDescriptor引用的数据源可以来自JNDI绑定的数据源, 也可以来自容器内定义的数据源(如上配置所示, 为了测试,我们使用了Spring容器内定义的C3P0数据源), 甚至其它形式提供的数据源, 只要为其提供标准的JDBC API中的DataSource接口实现即可.
DefaultCobarDataSourceService除了依赖一组CobarDataSourceDescriptor, 它还依赖于相应的IHADataSourceCreator来进行数据库的HA支持, 如果没有提供相应的IHADataSourceCreator实现类, DefaultCobarDataSourceService默认会使用NonHADataSourceCreator, 即不创建支持HA的数据源. CobarClient默认提供了FailoverHotSwapDataSourceCreator以支持HA, 应用方可以根据情况提供自己的IHADataSourceCreator实现来满足特定场景需要.
CobarClient支持基于双机热备的Failover, 该功能支持抽象为IHADataSourceCreator定义:
public interface IHADataSourceCreator {
DataSource createHADataSource(CobarDataSourceDescriptor descriptor) throws Exception;
}
前面我们说过, DefaultCobarDataSourceService在构建最终使用的数据源的时候, 通过某个IHADataSourceCreator来构建支持热切换的数据源实例. 最常见的IHADataSourceCreator实现类有com.alibaba.cobar.client.datasources.ha.NonHADataSourceCreator和com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator, 其中, NonHADataSourceCreator更多用于测试环境或者HA支持不需要CobarClient端支持的情况(比如,数据库部署层面支持HA之后, CobarClient端的HA可以不需要),所以, 如果使用CobarClient提供的HA支持, 更多的是指依赖引用FailoverHotSwapDataSourceCreator.
FailoverHotSwapDataSourceCreator支持基于主动探测形式的HA以及基于被动检测形式的HA, 这两种行为可以通过属性 “passiveFailoverEnable” 和 “positiveFailoverEnable” 来管理启用或者禁用, 其中, 基于主动探测形式的HA默认情况下是开启的, 而基于被动探测形式的HA是禁用的, 因为基于原来的Cobar(Server版)的现有经验, 每次取得数据库连接之后都进行状态检查会损耗性能.
要启用基于主动探测形式的HA支持, Cobar Client将Cobar(Server版)的HA方式适配借用过来, 需要你在数据库中配置相应的探测表, 并配置相应的探测用SQL. 例如, 假设数据库中建立了名为cobarha的状态探测表, 那我们可以设置如下的探测用SQL:
<bean id="haDataSourceCreator" class="com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator"> <property name="detectingSql" value="update cobarha set timeflag=CURRENT_TIMESTAMP()"/> </bean>
FailoverHotSwapDataSourceCreator将定时的发送该SQL到目标数据库, 对目标数据库的状态进行探测, 如果超时或者抛出异常, 那么重试指定次数之后依然如此的话, FailoverHotSwapDataSourceCreator会将目标数据库热切换到备用目标数据库上去. 探测的时间间隔, 探测的超市时间, 探测的重试次数等, 都可以通过相应的属性进行设置, 更多这方面的信息可以参考FailoverHotSwapDataSourceCreator的javadoc文档.
除了依赖某个ICobarDataSourceService进行多数据源的管理, CobarSqlMapClientTemplate的另一个主要依赖就是ICobarRouter, ICobarRouter负责将相应的数据访问请求路由到指定的数据源上去.
ICobarRouter抽象接口定义如下:
public interface ICobarRouter<T> {
RoutingResult doRoute(T routingFact) throws RoutingException;
}
该接口将根据指定的路由上下文信息(routingFact)返回最终的路由结果.
我们可以根据情况提供不同的ICobarRouter实现类, 比如Cobar Client默认提供的com.alibaba.cobar.client.router.CobarClientInternalRouter和om.alibaba.cobar.client.router.DefaultCobarClientInternalRouter, 或者如果路由规则数量很多, 为了保证性能, 也可以实现基于Rete等算法的实现类等. 没有特殊需求的情况下,我们默认采用CobarClientInternalRouter作为CobarSqlMapClientTemplate使用的默认Router实现. 但用户也可以根据情况选用DefaultCobarClientInternalRouter, 二者的使用是类似的。DefaultCobarClientInternalRouter在CobarClientInternalRouter的基础上, 对路由规则的匹配进行了分组优化, 通过配置时期的复杂度换取运行时期的简单高效。 如果规则很多的话,可以考虑使用DefaultCobarClientInternalRouter。
Note
DefaultCobarClientInternalRouter的配置可以通过两个专门的FactoryBean进行, 即com.alibaba.cobar.client.router.config.DefaultCobarClientInternalRouterXmlFactoryBean和com.alibaba.cobar.client.router.config.StaticCobarClientInternalRouterFactoryBean, 前者允许用户通过外部XML的配置文件形式来定义和加载路由规则, 后者运行用户直接在Spring的IoC容器中以bean定义的形式定义路由规则。 应用方可以根据情况选用。详细使用情况可以参考相应类的javadoc以及下面有关CobarClientInternalRouter的使用和配置信息。
因为CobarSqlMapClientTemplate主要面向iBatis, 所以, 它使用的CobarClientInternalRouter接受的路由上下文信息(routingFact)类型为IBatisRoutingFact:
public class IBatisRoutingFact {
// SQL identity
private String action;
// the argument of SQL action
private Object argument;
// ...
}
也就是说, CobarClientInternalRouter将根据两部分信息进行路由, 一就是sqlmap中的sqlmap id, 另一个就是传入的数据访问方法参数. CobarClientInternalRouter将根据一组或则多组路由规则对传入的IBatisRoutingFact类型的路由上下文信息进行匹配, 将匹配的结果返回, 之后, CobarClientInternalRouter就可以根据匹配的结果来决定最终的数据访问操作将在哪些数据源上执行了.
默认情况下, CobarClientInternalRouter将接收4组不同类型的路由规则, 但路由规则的类型对于用户来说实际上是不必要的, 所以, 为了避免用户过多的纠缠于CobarClientInternalRouter的实现细节, 我们给出了针对CobarClientInternalRouter配置的一个Spring的FactoryBean实现, 以帮助简化CobarClientInternalRouter的配置, 该FactoryBean实现类为com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean, 其一般的配置方式如下:
<bean id="internalRouter" class="com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean"> <property name="configLocation" value="classpath:META-INF/rules.xml" /> </bean>
CobarInteralRouterXmlFactoryBean将根据指定的xml形式的配置文件中的内容, 自动构建不同类型的路由规则, 然后注入到它将最终返回的CobarClientInternalRouter实例之上. 而读取, 解析配置信息, 并构建不同类型路由规则等 “琐事” 将完全对用户透明.不过, 再怎么屏蔽, 有得事情还是需要用户提供的, 比如配置文件的内容, 用户必须按照应用程序的部署情况提供正确地路由规则定义, CobarClientInternalRouter才会正确的工作.所以, 下面我们将详细介绍路由规则的相关信息.
Tip
除了可以通过configLocation属性指定单一的配置文件路径, 也可以通过configLocations指定多个配置文件路径,这通常有助于模块化并行开发.
Note
虽然默认情况下我们推荐使用CobarInteralRouterXmlFactoryBean进行CobarClientInternalRouter的配置, 但我们同样可以给出基于DSL甚至Excel等形式路由规则定义对应的FactoryBean.只要应用需要, 这些都是可以在现有的基础上进行扩展的.
一个最简单的路由规则定义文件内容可以如下所示:
<rules>
<rule>
<namespace></namespace>
<sqlmap></sqlmap>
<shardingExpression></shardingExpression>
<shards></shards>
</rule>
</rules>
<rules>下包含多个<rule>元素, 而<rule>下又包含4个子元素:
namespace 或者 sqlmap. 属于路由规则条件的一部分, 二者的唯一区别在于指定的条件明确程度不同, sqlmap直接对应每一个iBatis的SqlMap文件中某个statement的定义的id,而namespace则对应每一个iBatis的SqlMap文件中定义的namespace. 这两个元素在<rule>元素下只能取其一.否则在通过CobarInteralRouterXmlFactoryBean进行配置的时候, 将抛出配置相关异常.
shardingExpression. 遵循MVEL形式的表达式定义, 同样属于路由规则条件的一部分, 主要对数据访问请求的参数进行匹配, 属于动态条件, 通常用于横向切分规则的定义.
shards. 路由规则结果部分, 如果以上多个路由规则条件匹配成功, 则返回该元素的值作为路由结果.
以上rule定义简单来说表达了condition->action的语义, 即具体化为(namespace | sqlamp) + shardingExpression -> shards.
以上规则定义其实很简单,所以并不强制使用DTD或者XML Schema等来验证文档的合法性, 如果需要, 可以参考如下的DTD定义:
<?xml version="1.0"? encoding="UTF-8"?> <!ELEMENT rules (rule)+> <!ELEMENT rule ((namespace|sqlmap),shardingExpression,shards)> <!ELEMENT namespace (#PCDATA)> <!ELEMENT sqlmap (#PCDATA)> <!ELEMENT shardingExpression (#PCDATA)> <!ELEMENT shards (#PCDATA)>
那么, 以上元素到底应该如何根据应用程序的情况进行定义那? 让我们接着来看下一节的 “路由规则类型详解” 吧!
Note
CobarClient使用MVEL对shardingExpression进行求值, 所以, 起草的shardingExpression只要符合MVEL的语法就可以。有关MVEL的语法, 可以参考MVEL的 官方文档 。
路由规则的定义初看起来简单, 但到底应该如何定义, 以及为什么要如此定义, 在没有为你揭开这些疑问之前,我想, 你还是很难搞清楚这些路由规则定义到底是怎么回事, 不过没关系, 我们现在就为你揭开这些疑团.
在使用iBatis进行数据访问的时候,我们通常会定义相关的SqlMap文件, 例如:
<?xml version="1.0" encoding="GB2312"?>
<!DOCTYPE sqlMap PUBLIC "-//iBATIS.com//DTD SQL Map 2.0//EN" "http://www.ibatis.com/dtd/sql-map-2.dtd">
<sqlMap namespace="com.alibaba.cobar.client.entities.Offer">
<typeAlias alias="offer" type="com.alibaba.cobar.client.entities.Offer" />
<resultMap id="offer" class="offer">
<result property="id" column="id" />
<result property="memberId" column="memberId" />
<result property="subject" column="subject" />
<result property="gmtUpdated" column="gmtUpdated" />
</resultMap>
<insert id="create">
INSERT INTO offers(memberId, subject, gmtUpdated) VALUES(#memberId#, #subject#, #gmtUpdated#)
<selectKey keyProperty="id" resultClass="long">
SELECT LAST_INSERT_ID();
</selectKey>
</insert>
...
</sqlMap>
其中, 每个SqlMap都会对应一个namesapce, 在该namespace下, 可以定义多个sql statement, 而每个statement又会有相应的id作为其标志, 其中, namespace + id可以唯一标志一个全局的sql statement, 在这一前提下, 让我们来看如何根据现有iBatis的SqlMap的定义来进行数据访问的路由.
我们本着从特殊到一般的情况进行推演.
以create操作为例, 假设我们的offer数据现在分布在两台数据库上, 而根据切分规则, memberId为奇数的数据分布在数据库1上, memberId为偶数的数据分布在数据库2上, 在这一前提下, 要路由offer的创建相关的数据请求, 最明了的方式就是, 检查当前数据访问对应的sql statement是哪个, 并判断传入的参数包含的memberId是奇数还是偶数, 这样, 我们就有了以下2个路由规则定义:
<rules>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shardingExpression>memberId % 2 == 1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shardingExpression>memberId % 2 == 0</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
<sqlmap>元素对应唯一的sql statement标志, 即namespace + sql statement id, <shardingExpression>对应切分规则的定义, 而<shards>则对应最终的路由结果. 现在, 我想你应该对路由规则的如上定义有了初步的了解了吧!
有了以上的基础, 我们来变换假设场景, 我们依然是create操作, 但现在我们不是做的水平切分, 而只是做垂直切分, 也就是说, 所有的offer数据现在假设都会落在同一台数据库上, 那么, 以上的定义可以变更为:
<rules>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shardingExpression>memberId % 2 == 1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shardingExpression>memberId % 2 == 0</shardingExpression>
<shards>partition1</shards>
</rule>
</rules>
即不管切分规则如何, 他们的合集都是落在partition1上, 可是, 如果真的这么定义的话, 那看起来是不是有些stupid那? 答案肯定是yes, 所以, 对应这种情况, 我们的路由规则可以定义如下:
<rules>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shards>partition1</shards>
</rule>
</rules>
也就是说, 我们现在只定义sqlmap元素, 而忽略shardingExpression元素的定义, 以上rule定义就好像再说 “只要我发现sqlmap的值是com.alibaba.cobar.client.entities.Offer.create, 那就将匹配的数据访问请求路由到partition1, 而不管参数中的memberId或者其它数据具体是什么” .
我们将第一种形式的路由规则成为SqlActionShardingRule, 而将第二种形式的路由规则称为SqlAction(Only)Rule, 分别用于明确的指定在水平切分和垂直切分情况下的路由规则定义.
现在让我们进一步扩展场景, 显然, 除了要创建offer, 我们还要提供更新或者删除等数据操作, 那么, 自然而然的,我们就需要在SqlMap文件中定义更多的sql statement, 如下所示:
<?xml version="1.0" encoding="GB2312"?>
<!DOCTYPE sqlMap PUBLIC "-//iBATIS.com//DTD SQL Map 2.0//EN" "http://www.ibatis.com/dtd/sql-map-2.dtd">
<sqlMap namespace="com.alibaba.cobar.client.entities.Offer">
<typeAlias alias="offer" type="com.alibaba.cobar.client.entities.Offer" />
<resultMap id="offer" class="offer">
<result property="id" column="id" />
<result property="memberId" column="memberId" />
<result property="subject" column="subject" />
<result property="gmtUpdated" column="gmtUpdated" />
</resultMap>
<insert id="create">
INSERT INTO offers(memberId, subject, gmtUpdated) VALUES(#memberId#, #subject#, #gmtUpdated#)
<selectKey keyProperty="id" resultClass="long">
SELECT LAST_INSERT_ID();
</selectKey>
</insert>
<update id="update">
UPDATE offers SET subject=#subject#, gmtUpdated=#gmtUpdated# WHERE id=#id#
</update>
<delete id="delete">
delete from offers where id=#id#
</delete>
...
</sqlMap>
如果只有SqlActionShardingRule和SqlAction(Only)Rule的支持, 要保证更新和删除操作能够被正确的路由到指定的数据库, 我们就得根据切分规则, 再路由规则定义文件中再为更新和删除操作添加相应的路由规则定义. 这样做的问题在于:
没添加一个针对某表的SqlMap文件, 就需要在路由规则定义文件中添加一系列的CURD操作对应的路由定义, 从使用的角度来看, 很繁琐;
通常针对某个表的操作, 切分规则都是相同的, 不管具体数据访问操作是什么, 也就是说, 通常定义一套路由规则, 原则上来讲应该可以满足CURD多个数据操作的路由.
鉴于以上两点,我们又引入了NamespaceShardingRule和Namespace(Only)Rule的概念.
NamespaceShardingRule允许我们基于SqlMap中的namespace和水平切分规则进行路由规则的定义, 同样针对最初的切分规则, 即memberId为奇数的数据落在数据库1上, 而memberId为偶数的数据落在数据库2上, 那不管其操作是创建还是更新, 只要数据访问对应的sql statement落在指定的namespace下(对应我们的情况就是com.alibaba.cobar.client.entities.Offer命名空间), 并且数据访问参数符合指定的切分规则, 我们就可以正确的路由数据访问请求, 最终我们可以给出如下的路由规则定义:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>memberId % 2 == 1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>memberId % 2 == 0</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
进一步的,如果所有数据只是水平切分, 那跟SqlActionShardingRule和SqlAction(Only)Rule的差别类似, 我们也可以只使用Namespace(Only)Rule:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shards>partition1</shards>
</rule>
</rules>
现在, 定义在com.alibaba.cobar.client.entities.Offer命名空间下的所有sql statement, 将全部被路由到partition1数据库执行.
可以看到, 从SqlActionShardingRule到SqlAction(Only)Rule, 一直到NamespaceShardingRule和Namespace(Only)Rule, 路由规则涵盖的面是从特殊到一般层面逐步放开的, 如果针对某个sql statement有特殊的路由需求, 那么可以根据情况添加相应的SqlActionShardingRule或者SqlAction(Only)Rule, 而如果多个sql statement拥有相近或者相同的路由需求, 那么, 就可以根据情况归纳并添加相应的NamespaceShardingRule或者Namespace(Only)Rule, 总之, 这四种类型的Rule类型可以组合使用, 全面的覆盖整个基于iBatis的数据访问请求的路由.
Tip
在定义路由规则的过程中,可以从一般情况下的NamespaceShardingRule或者Namespace(Only)Rule着手, 首先定义一般情况下的路由规则, 然后在根据某些特殊数据访问请求, 进一步添加SqlActionShardingRule或者SqlAction(Only)Rule类型的路由规则. CobarClientInternalRouter在进行路由的时候, 将首先进行特殊情况下的路由规则匹配, 当找不到匹配规则的时候, 在进一步的使用一般的路由规则作为后备规则进行匹配.
常见的水平切分规则有:
基于范围的切分, 比如 memberId > 10000 and memberId < 20000
基于模数的切分, 比如 memberId%128==1 或者 memberId%128==2 或者...
基于哈希(hashing)的切分, 比如hashing(memberId)==someValue等
另外, 还有诸如predicate-based partitioning等, 为了满足不同切分规则定义的需要, 我们运行在路由规则定义的时候, 在shardingExpression中使用自定义的路由规则函数.
下面我们以一个简单的实例来说明在Cobar Client中如何自定义使用路由规则函数.
假设我们要按照某种hashing算法对memberId进行散列, 并根据散列的值进行路由, 那么首先,我们需要定义一个函数类, 该类将根据传入的memberId返回相应的散列结果:
public class Hashing{
...
int apply(Long memberId){
// perform real logic here.
}
}
有了该函数定义,我们希望在shardingExpression中使用它, 那首先我们需要注册该函数, 这通过CobarInteralRouterXmlFactoryBean的 “functionsMap” 属性进行:
<bean id="internalRouter" class="com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean"> <property name="functionsMap"> <map> <entry key="hash"> <bean class="..Hashing"> </bean> </entry> </map> </property> <property name="configLocations"> <list> <value>classpath:META-INF/routing/offer-sql-action-rules.xml</value> <value>classpath:META-INF/routing/offer-sharding-rules-on-namespace.xml</value> </list> </property> </bean>
注意,我们以hash作为key对以上自定义函数进行了注册.
有了以上准备之后, 我们就可以在shardingExpression中使用该自定义函数了:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>hash.apply(memberId) == someValue</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>hash.apply(memberId) == anotherValue</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
可见只要使用注册时用的key作为对象应用针对指定的表达式字段调用相应的方法就是了. 简单, 却不失强大.
CobarSqlMapClientTemplate提供了针对SQL的分析和记录扩展接口,但没有给出相应的实现, 因为国际站现在可以通过Ark项目来完成同样的目的, 但如果需要, 可以给出一个ISqlAuditor接口实现, 然后注入给CobarSqlMapClientTemplate.
ISqlAuditor接口定义很简单:
public interface ISqlAuditor {
void audit(String id, String sql, Object sqlContext);
}
其中, 参数"id"标志执行的iBatis的sqlmap的id; 参数 “sql” 表示id对应的SQL, 如果id对应的SQL是DynamicSql的话, 该参数为null; 最后参数sqlContext对应具体传入的参数对象. 应用程序可以根据具体场景来决定如何实现某个ISqlAuditor以及如何使用这些参数.为了不影响性能, 提供的ISqlAuditor尽量采用异步的方式进行处理, 不要同步阻塞后续的数据访问请求的处理.
如果为CobarSqlMapClientTemplate注入某个ISqlAuditor的实现, 那么默认情况下CobarSqlMapClientTemplate会检查用户是否同时注入了一个伴随的ExecutorSerivce, 该伴随的ExecutorService主要是为了避免用户提供的ISqlAuditor没有进行合适的异步处理策略从而拖累CobarSqlMapClientTemplate的情况发生, 如果用户没有提供这样一个ExecutorService, 那CobarSqlMapClientTemplate会默认初始化一个拥有一个worker thread的ExecutorService. 原则上用户不需要干预该ExecutorService, 但如果调整该参数对CobarSqlMapClientTemplate的性能有帮助的话,那可以通过 sqlAuditorExecutor 属性来注入一个外部的ExecutorService.
应监控需求, 我们在CobarSqlMapClientTemplate中加入了记录长时间运行的SQL功能, 该功能默认情况下为不开启,如果要开启该功能, 可以通过设置 profileLongTimeRunningSql 属性来完成. 设置 profileLongTimeRunningSql 的同时, 我们同时要求提供监控的SQL运行时间的限定标准, 即 longTimeRunningSqlIntervalThreshold , 如果用户提供的longTimeRunningSqlIntervalThreshold小于或者等于零, 在CobarSqlMapClientTemplate初始化的时候将抛出异常, 以阻止用户使用非状态完备的CobarSqlMapClientTemplate实例.
配置该功能的简单实例如下:
<bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> ... <property name="profileLongTimeRunningSql" value="true" /> <property name="longTimeRunningSqlIntervalThreshold" value="3600000" /> </bean>
某些情况下, 应用程序可能会通过 “INSERT INTO tab(..) VALUES(..), (..), (..), (..)...” 形式的SQL进行批量的数据插入, 为了支持这种情况, CobarSqlMapClientTemplate允许通过BatchInsertTask来提交批量的插入数据, 当CobarSqlMapClientTemplate发现在insert(..)的时候用户传入的是BatchInsertTask类型的参数的话, 它首先会根据路由规则对提交的批量数据进行重新归类, 将发送到不同DataSource的数据归类到不同的队列中, 归类完成之后, 再并行的提交给不同的DataSource执行.
该功能可以避免应用程序端自行进行数据归类提交等操作, 同时又可以有效的利用现有的路由规则, 数据的最终流向可以对应用程序透明.
假设我们有数据对象如下:
public class Offer {
private Long id;
private Long memberId;
private String subject;
private Date gmtUpdated = new Date();
// setters and getters and other method definitions
}
而且我们有如下的路由规则定义:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>memberId < 10000</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>memberId > 10000 and memberId < 20000</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
当我们通过BatchInsertTask提交一批Offer数据并提交CobarSqlMapClientTemplate执行之后, 提交的这批Offer数据将按照路由规则分类之后, 批量插入数据库.
Note
为了更明确该批量插入行为, 我们也可以定义更确切的路由规则, 比如直接提升路由规则为基于SqlAction的Sharding规则, 这样, 该规则就可以更确切的应用到针对某一SqlAction的批量插入操作上.
在CobarClient中, 数据的merge功能还比较弱, 这跟Cobar(Server版)是类似的,基本上是遵循Cobar(Server版)的现有状况, 即只将每个数据源返回的数据结果添加到List形式的结果对象中返回。 这时候, 可能就需要应用程序在使用的时候根据情况自行提取并处理最终返回的结果对象。 比如, 如下的SQL执行:
select count(*), companyId from offer group by companyId
当其对应的路由规则对应多个数据源的时候, 该条语句将会在这多个数据源上执行, 并返回各自的结果,这些各自返回的结果将被添加到一个List当中返回, 那么, 该List中将包含多个(Count, companyId)的组合, 同一companyId会存在多个纪录, 应用程序可能需要将List中的这些纪律加总后使用。
现在的CobarClient对所有的查询结果进行merge都是按照这种方式进行的, 所以, 应用程序在使用过程中应该注意这种情况对应用可能造成的影响。 CobarClient后期将逐步完善数据的merge策略, 比如可以允许应用程序指定自定义的merge策略。
如果通过CobarSqlMapClientTemplate的queryForList()方法进行数据查询, 并且查询语句中存在order by的情况, 按照CobarSqlMapClientTemplate的默认merge策略, 最终总体的查询结果的顺序是不保证的, 但如果用户希望能够在现有每个单独结果集合已经排序的情况下对最终结果进行整体的排序, CobarSqlMapClientTemplate允许这种情况下用户指定使用自定义的merge策略。 这实际上类似于在merge sort算法中, 数据库帮我们做了前半部分工作, 而后半部分则由我们自己来执行。
要使用自定义的merge策略,用户可以通过 CobarSqlMapClientTemplate的 “mergers” 属性指定一组SqlMapActionId到具体自定义merge策略实现类之间的映射关系。 例如:
<bean id="sqlMapClientTemplateWithMerger" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> <property name="router" ref="internalRouter" /> <property name="sqlAuditor"> <bean class="com.alibaba.cobar.client.audit.SimpleSqlAuditor" /> </property> <property name="profileLongTimeRunningSql" value="true" /> <property name="longTimeRunningSqlIntervalThreshold" value="3600000" /> <property name="mergers"> <map> <entry key="com.alibaba.cobar.client.entities.Offer.findAllWithOrderByOnSubject" value-ref="merger" /> </map> </property> </bean> <bean id="merger" class="com.alibaba.cobar.client.merger.ConcurrentSortMerger"> <property name="comparator" ref="comparator"> </property> </bean> <bean id="comparator" class="com.alibaba.cobar.client.support.OfferComparator"> </bean>
以上代码实例中, 我们指定针对使用 “com.alibaba.cobar.client.entities.Offer.findAllWithOrderByOnSubject ” 的查询操作, 其最终结果需要使用 “merger” 进行合并, 而 “merger” 通常是用户根据最终查询结果集合的属性提供的自定义IMerger实现, 在这里, 我们使用了com.alibaba.cobar.client.merger.ConcurrentSortMerger, 大部分情况下, 该实现类可以满足应用的需求,用户只需要根据情况提供不同的Comparator即可。
Note
实际上, 这种处理方式可能看起来会比较繁琐, 因为排序的信息可以通过分析SqlMapActionId对应的SQL推导出来, 但目前只是为了提供简单的merge功能支持, 不想引入过多的复杂性。而且, 对于DynamicSql来说, 具体的SQL在应用层是取不到的, 因为即使是通过分析SQL也不可能保证任何情况下的推导信息可以获得。
如果需要, 后继版本中可以推出基于SQL解析来推导数据merge逻辑的支持。
根据国际站需求, CobarClient需要保证多个数据库之间的本地事务, 但不接受分布式事务,因为分布式事务可能引入不必要的性能问题. 在这种前提条件下,我们最终敲定使用Best Efforts 1PC Pattern来实现CobarClient的事务管理.
CobarClient提供了自定义的事务管理器MultipleDataSourcesTransactionManager来支持基于Best Efforts 1PC Pattern的事务管理, MultipleDataSourcesTransactionManager接受一组数据源作为事务的目标资源,当事务开始的时候, 开启所有数据源相关的本地事务, 事务提交或者回滚的时候, 则同时提交或者回滚所有的本地事务. 同时开始所有数据源上的本地事务,默认情况下,自然会占用每一个数据源的一个物理连接, 进而可能造成性能问题, 所以, 我们对依赖的数据源进行了拦截, 加入了一层LazyConnectionDataSourceProxy, 该LazyConnectionDataSourceProxy将保证只有存在确切的数据访问操作的时候, 才会真正的从目标数据源中获取真正的物理连接,也正如架构图中(1)和(2)所标注的那样.
实际上, 为了避免不必要的物理连接的占用, 我们也可以在事务定义中加入相应的标志数据来表明要在哪些资源之上开启本地事务, 这可以通过在Service层次标注Annotation或者附带外部配置文件的形式实现. 不过, 可能有人会认为这会一定程度的侵入service层,所以, 暂时还是采用MultipleDataSourcesTransactionManager加上LazyConnectionDataSourceProxy的组合来完成基于Best Efforts 1PC Pattern的事务管理.
要保证事务加诸于相同的一组数据源之上, 我们需要为MultipleDataSourcesTransactionManager注入与CobarSqlMapClientTemplate相同的一组数据源依赖, 这同样是通过ICobarDataSourceService类保证的:
<bean id="transactionManager" class="com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager"> <property name="cobarDataSourceService" ref="dataSources" /> </bean> <bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> ... </bean> <bean id="dataSources" class="com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService"> <property name="dataSourceDescriptors"> <set> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition1"/> <property name="targetDataSource" ref="partition1_main"/> <property name="targetDetectorDataSource" ref="partition1_main"/> <property name="standbyDataSource" ref="partition1_standby"/> <property name="standbyDetectorDataSource" ref="partition1_standby"/> </bean> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition2"/> <property name="targetDataSource" ref="partition2_main"/> <property name="targetDetectorDataSource" ref="partition2_main"/> <property name="standbyDataSource" ref="partition2_standby"/> <property name="standbyDetectorDataSource" ref="partition2_standby"/> </bean> </set> </property> <property name="haDataSourceCreator"> <bean class="com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator"> <property name="detectingSql" value="update cobarha set timeflag=CURRENT_TIMESTAMP()"/> </bean> </property> </bean> ...
总的来说, MultipleDataSourcesTransactionManager的使用其实就这么简单(有关com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService的更多信息, 请参考 ??? 相关内容.). 如果要了解更多配置细节, 可以参考Spring的AbstractPlatformTransactionManager或者MultipleDataSourcesTransactionManager的javadoc.