Abstract
This document describes all of the information of Cobar Client product.
Table of Contents
- I. Migrate To Cobar Client
- II. Cobar Client Bible
- 2. The Background of Why CobarClient Was Launched
- 3. Initial Requirements of CobarClient
- 4. Possible Strategies for CobarClient Design and Development
- 5. Cobar Client Reference Documentation
- 6. CobarClient Possible RoadMaps In The Future
Cobar Client is mainly for the applications who is using iBatis as the data access layer. If you have used Spring's SqlMapClientTemplate with iBatis and you also want to achieve distributed data access abilities, then Cobar Client is for you. Furthermore, it will be much easier to migrate your application(s) to use Cobar Client to do data access stuffs. Here is how to.
Suppose your applications are now depending on Spring's SqlMapClientTemplate to do data access stuffs, to migrate to Cobar Client, What you need to do is just to change from Spring's SqlMapClientTemplate to Cobar Client's CobarSqlMapClientTemplate. Meantime, to sync up transaction management, the original DataSourceTransactionManager of spring framework has to be change to MultipleDataSourcesTransactionManager of Cobar Client. The configuration changes is listed below with 2 snippets in contrast with each other:
Before using CobarClient: <bean id="sqlMapClientTemplate" class="org.springframework.orm.ibatis.SqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient"/> ... </bean> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource"/> ... </bean> <bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="configLocation" value="classpath:META-INF/ibatis/sqlmap-config.xml" /> </bean> <bean id="dataSource" ...> ... </bean>
After using CobarClient: <bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient"/> ... </bean> <bean id="transactionManager" class="com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager"> ... </bean> <bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="configLocation" value="classpath:META-INF/ibatis/sqlmap-config.xml" /> </bean> <bean id="dataSource" ...> ... </bean>
As you can see, only 2 placements in the configuration need to be changed to complete the whole migration.
OK, I lied, the above sample is a scenario that has been simplified, in fact, to complete the whole migration, there are more details we need to take care of.
In the situation of single data source, SqlMapClientTemplate(or the SqlMapClient it depends) and DataSourceTransactionManager it will used to manage transaction both will refer to a single same data source. But when the data has been splitted into different partitions/shards, the applications maybe have to access multiple data sources to complete single data acess request. To manage these multiple data sources as dependencies in a consistent and easy way, CobarClient provides “ICobarDataSourceService” as the top abstraction on this concern. “ICobarDataSourceService” will manage multiple data sources that will be used by both “com.alibaba.cobar.client.CobarSqlMapClientTemplate” and “com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager ” . “com.alibaba.cobar.client.CobarSqlMapClientTemplate” and “com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager ” will now depend on some implementation of “ICobarDataSourceService” to provide data sources dependency. So, now the original configuration will become to:
<bean id="dataSources" class="Some ICobarDataSourceService Implementation Class"> ... </bean> <bean id="transactionManager" class="com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager"> <property name="cobarDataSourceService" ref="dataSources" /> </bean> <bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> ... </bean> <bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="configLocation" value="classpath:META-INF/ibatis/sqlmap-config.xml" /> </bean>
That's, both “MultipleDataSourcesTransactionManager” and “CobarSqlMapClientTemplate” will have a same cobarDataSourceService dependency which is the bean definition named dataSources in our configuration snippet above. The bean definition will define a bean who is an implementation of “ICobarDataSourceService” . For now, we provide a default implementation - “com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService ” . Here follows a sample configuration snippet we may use:
<bean id="dataSources" class="com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService"> <property name="dataSourceDescriptors"> <set> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition1"/> <property name="targetDataSource" ref="partition1_main"/> <property name="targetDetectorDataSource" ref="partition1_main"/> <property name="standbyDataSource" ref="partition1_standby"/> <property name="standbyDetectorDataSource" ref="partition1_standby"/> </bean> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition2"/> <property name="targetDataSource" ref="partition2_main"/> <property name="targetDetectorDataSource" ref="partition2_main"/> <property name="standbyDataSource" ref="partition2_standby"/> <property name="standbyDetectorDataSource" ref="partition2_standby"/> </bean> </set> </property> <property name="haDataSourceCreator"> <bean class="com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator"> <property name="detectingSql" value="update cobarha set timeflag=CURRENT_TIMESTAMP()"/> </bean> </property> </bean> <bean id="partition1_main" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="org.h2.Driver" /> <property name="jdbcUrl" value="jdbc:h2:mem:p1_main;DB_CLOSE_DELAY=-1;MODE=MySQL;LOCK_MODE=3" /> <property name="user" value="" /> <property name="password" value="" /> <property name="minPoolSize" value="10" /> <property name="maxPoolSize" value="20" /> <property name="maxIdleTime" value="1800" /> <property name="acquireIncrement" value="2" /> <property name="maxStatements" value="0" /> <property name="initialPoolSize" value="2" /> <property name="idleConnectionTestPeriod" value="1800" /> <property name="acquireRetryAttempts" value="30" /> <property name="breakAfterAcquireFailure" value="true" /> <property name="testConnectionOnCheckout" value="false" /> </bean> <bean id="partition1_standby" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="org.h2.Driver" /> <property name="jdbcUrl" value="jdbc:h2:mem:p1_standby;DB_CLOSE_DELAY=-1;MODE=MySQL;LOCK_MODE=3" /> <property name="user" value="" /> <property name="password" value="" /> <property name="minPoolSize" value="10" /> <property name="maxPoolSize" value="20" /> <property name="maxIdleTime" value="1800" /> <property name="acquireIncrement" value="2" /> <property name="maxStatements" value="0" /> <property name="initialPoolSize" value="2" /> <property name="idleConnectionTestPeriod" value="1800" /> <property name="acquireRetryAttempts" value="30" /> <property name="breakAfterAcquireFailure" value="true" /> <property name="testConnectionOnCheckout" value="false" /> </bean> <bean id="partition2_main" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="org.h2.Driver" /> <property name="jdbcUrl" value="jdbc:h2:mem:p2_main;DB_CLOSE_DELAY=-1;MODE=MySQL;LOCK_MODE=3" /> <property name="user" value="" /> <property name="password" value="" /> <property name="minPoolSize" value="10" /> <property name="maxPoolSize" value="20" /> <property name="maxIdleTime" value="1800" /> <property name="acquireIncrement" value="2" /> <property name="maxStatements" value="0" /> <property name="initialPoolSize" value="2" /> <property name="idleConnectionTestPeriod" value="1800" /> <property name="acquireRetryAttempts" value="30" /> <property name="breakAfterAcquireFailure" value="true" /> <property name="testConnectionOnCheckout" value="false" /> </bean> <bean id="partition2_standby" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> <property name="driverClass" value="org.h2.Driver" /> <property name="jdbcUrl" value="jdbc:h2:mem:p2_standby;DB_CLOSE_DELAY=-1;MODE=MySQL;LOCK_MODE=3" /> <property name="user" value="" /> <property name="password" value="" /> <property name="minPoolSize" value="10" /> <property name="maxPoolSize" value="20" /> <property name="maxIdleTime" value="1800" /> <property name="acquireIncrement" value="2" /> <property name="maxStatements" value="0" /> <property name="initialPoolSize" value="2" /> <property name="idleConnectionTestPeriod" value="1800" /> <property name="acquireRetryAttempts" value="30" /> <property name="breakAfterAcquireFailure" value="true" /> <property name="testConnectionOnCheckout" value="false" /> </bean>
DefaultCobarDataSourceService has a group of com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor references, and each “com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor ” depicts the necessary dependencies of each data partition/shard. These necessary dependencies are:
identity. The identity of data partition/shard, it should not collide with others'. When defining routing rules, the identity will be used as part of the rules.
targetDataSource. the main target data source reference, in general, when the application is launched, this data source must be active.
targetDetectorDataSource. paired with main target data source, this data source reference is used to detect the status of the main target data source so that HA operations can be performed at right timing. This data source must be configured independently so that it will not interfere with the others.
standbyDataSource. When HA functionality is enabled and the main target data source is down, CobarClient will switch to use this data source instead of main target data source.
standbyDetectorDataSource. detetor data source for standby target data source. It should be configured independently too, just like “targetDetectorDataSource” .
Note
Since the data sources are retrieved via JNDi when Cobar Client was launched, so we have to set up another paired data source to use for detecting target database status. The reason is We can't get the exact configuration information of the data source bound to JNDI, so we can't create a paired data source for detecting database status by ourselves. If we do, we can create paired data sources by ourselves as per single piece of configuration information.
Currently, CobarDataSourceDescriptor only contains necessary information for specific database deployment structure, that's, 2 Master Active Database deployment structure. Later on, as requirement changes, it may be adapted to meet the needs of different scenarios.
Tip
If 2 master active HA functionality is not needed, then we can point “standby(.*)DataSource” to “target(.*)DataSource” , or just ignore configuring the “haDataSourceCreator” attribute of DefaultCobarDataSourceService,then it's not necessary to configure “standbyDataSource” , “standbyDetectorDataSource” and “targetDetectorDataSource” attributes.
CobarDataSourceDescriptor can refer to diffrent data sources, like the ones from JNDI, or the ones that are in local containers(e.g. for test purpose, we use C3P0 implementation in spring ioc container.), even other types of data sources, as long as they conform to standard JDBC “DataSource” API.
DefaultCobarDataSourceService not only depends on a group of CobarDataSourceDescriptor, but also depends on an “IHADataSourceCreator” to supoort HA functionality. If no “IHADataSourceCreator” implementation is given, DefaultCobarDataSourceService will use “NonHADataSourceCreator” as default, that's, not create HA-enabled data sources. If HA is needed, FailoverHotSwapDataSourceCreator of CobarClient is available, of course, if needed, the application can implement their own IHADataSourceCreator implementations.
The concern on how to manage multiple data sources of different database partitions/shards is done here, next, let check out other configuration details...
com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager is a standard extension of PlatformTransactionManager in spring framework, so except for “ICobarDataSourceService” dependency which is speicific to CobarClient, all of the other things are inherited from spring “AbstractPlatformTransactionManager” , so we will not explain too much on it, the users can refere to spring documentation for details and further help. In this section, we mainly explain more on CobarSqlMapClientTemplate's other dependencies.
CobarSqlMapClientTemplate depends on some “ICobarDataSourceService” implementation to get information of different data partitions/shards, furthermore, in order to know where to route the data access requests, it also depends on an “ICobarRouter” implementation to help on data access routing. So with an “ICobarRouter” implementation available, we get a well-configured CobarSqlMapClientTemplate below:
<bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> <property name="router" ref="internalRouter" /> <property name="sqlAuditor"> <bean class="com.alibaba.cobar.client.audit.SimpleSqlAuditor" /> </property> <property name="profileLongTimeRunningSql" value="true" /> <property name="longTimeRunningSqlIntervalThreshold" value="3600000" /> </bean> <bean id="internalRouter" class="com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean"> <property name="functionsMap"> <map> <entry key="mod"> <bean class="com.alibaba.cobar.client.router.rules.support.ModFunction"> <constructor-arg><value>128</value></constructor-arg> </bean> </entry> </map> </property> <property name="configLocations"> <list> <value>classpath:META-INF/routing/offer-sql-action-rules.xml</value> <value>classpath:META-INF/routing/offer-sharding-rules-on-namespace.xml</value> </list> </property> </bean>
Note
As to configuration items like “sqlAuditor” , “profileLongTimeRunningSql” , or “longTimeRunningSqlIntervalThreshold” , they are optional, more details can be found in CobarClient Reference.
Default Implementation of ICobarRouter is com.alibaba.cobar.client.router.CobarClientInternalRouter , in order to simplify configuration things, A FactoryBean is also provided, that's, com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean. The main configuration item of it is “configLocations” (or configLocation, if only one routing rule file is available) which specify the locations of routing rule files, com.alibaba.cobar.client.router.CobarClientInternalRouter will use the rules in these files to decide on deata access routing. Here is a sample routing rule file:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>mod.apply(memberId)==1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>mod.apply(memberId)==2</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
In the “shardingExpression” of the routing rule, a custom function is used(mod.apply(..)), this custom function is defined by ourselves, After it is defined, we can pass it in via “functionsMap” attribute of com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean, then we can use it in the routing rule expressions.
The routing rules definition is very simple, so it's not necessary to make it mandatory to use DTD or XML Schema. But if you indeed want it, a smiple description on DTD of routing rules is listed below:
<?xml version="1.0"? encoding="UTF-8"?> <!ELEMENT rules (rule)+> <!ELEMENT rule ((namespace|sqlmap),shardingExpression,shards)> <!ELEMENT namespace (#PCDATA)> <!ELEMENT sqlmap (#PCDATA)> <!ELEMENT shardingExpression (#PCDATA)> <!ELEMENT shards (#PCDATA)>
Routing Rules can be classified into 4 types, you can find more details in CobarClient Reference. Anyway, with routing rule definitions above, distributed data access can be achieved by using CobarClient.
We alibaba have a “Cobar” project already which does help on distributed data access, but in order to meet the HA and performance requirements, two or more servers are needed to make it run. Usually it's not a good choice for small applications which still need distributed data access abilities. Since the technology department of ICBU(Alibaba) requires a lightweight but still powerful solution on distributed data access requirement, CobarClient(Version) comes into the play.
CobarClient is mainly for specific usage scenarios, that's, distributed data access on small or modest scale database shardings/partitions. So before you decide whether to use CobarClient, leverage your application scenario first. (For Alibaba Internal, if CobarClient can't meet your needs, you can turn to Cobar instead.)
CobarClient must support following functionalities:
data access support with horizontal or vertical partitions.
support 2-master active HA deployment infrustructure, of course, the applications still can choose other HA solutions, like the ones specific to destination databases(e.g. RAC of Oracle).
Data aggregation support, currently only simple data merge functionality is available.
Local database transaction support(Currently, such requirement is fulfilled by using “Best Efforts 1PC Pattern” ).
SQL auditing, analysis, etc. [1]
[1] ICBU Internal can use their old “Ark” solution to do such works, but CobarClient still provides extension point for this.
The Design and Development of CobarClient can be done from different aspects, but we choose three solutions for it for the time being.
The available “Cobar” project do data access routings by parsing and analyzing SQL, so most of us will think it's easy to do almost same things by wrapping the JDBC drivers. Of course, it should work, but it takes time, long time.
To do things in this way, we can't just wrap or intercept several JDBC interfaces to make it run, we need to implement the whole JDBC specification, and it will take too much time on development and testing.
At first, we just try to intercept serveral methods of “Connection” and “Statement” to get the SQL and then parse it to do left works, but several headaches come to bother. You will find that several methods' lifecycle and invocation logic will mismatch with each other, you will find you have to trace the method invocation sequences, you will also find you have to take care of all of the database metadata things.
You see, we do can implement a whole JDBC driver to do works like current “Cobar” does, but it's not an easy thing with limit time frame.
We can do the same thing on DAL. Many benefits are avaialble, including that:
we can make a standard development process;
we can simplify the implementation of data access routing;
furthermore, if more shards or other storage services(e.g. KV store) are required, the applications won't need any changes, 'cause the DAL has hidden these changes for them.
If we do use such solution on DAL, we can externalize the sharding strategies and rules, the routing rules can be configured in a consistent way(Annotation, or external XML configuration files), and the rules can be defined only as per the type of DO(Data Object) and their attributes. It's so simple and flexible, the complexity of SQL parsing is involved.
But such solution impacts too much to the current applications, so althought it's a good go, we can't make it run for the time being.
After thinking on multiple factors like the time frame limitation, the compatibility to available applications, etc, we give out a solution that stands between JDBC API Layer Solution and DAL(Data Access Layer) Solution .
We internally use iBatis to do data access, in order to accelerate the development process, we use SqlMapClientTemplate of spring framework, too. To make less impacts on current applications, we have to extend the SqlMapClientTemplate class, because all of the data access requests will be sent out by this class, and if we add routing support in it, then it can route different data access requests to their specific data shards as per the routing rules we provide.
In fact, this is indeed the solution we choose to use in the 1st version of CobarClient.
The architecture of CobarClient looks like:
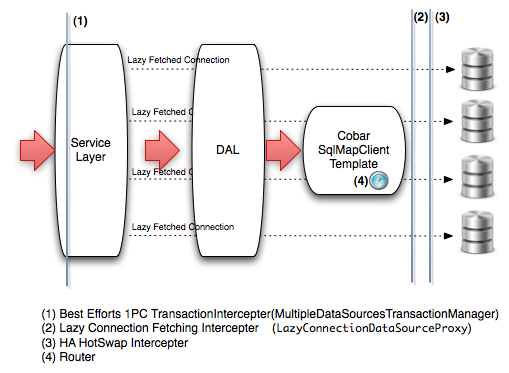
This architecture will take care of two main concerns:
Routing of Data Access Requests. By extending spring's SqlMapClientTemplate, we provide our own CobarSqlMapClientTemplate. CobarSqlMapClientTemplate will work with some “Router” to support data access routing. It keeps compatible with current applications, the migration is simplified to just replace and inject SqlMapClientTemplate instances to your application.
Transaction Management on Multiple DataSources. Since 2PC(2Phase Commit) will cause performance penalty, it's not proper to use 2PC distributed transaction management strategy for web applications. But since transaction management is still needed, so we turn to use “Best Efforts 1PC Pattern” transaction management. MultipleDataSourcesTransactionManager is the transaction manager that's implemented with “Best Efforts 1PC Pattern” , it extends AbstractPlatformTransactionManager of spring framework, so by just replacing your original transaction manager implementations with MultipleDataSourcesTransactionManager to use it. MultipleDataSourcesTransactionManager has a good balance between the performance and data integration.
Furthermore, we also add HA support between data sources by using AOP, and enable lazy-loading database connections to use resources efficiently. All of these functionalities can be found in above architecture picture.
We will start to introduce each aspects of CobarClient, since the 2 main concerns are the most important things, we will start from them. So here we go...
CobarSqlMapClientTemplate is an extension of standard SqlMapClientTemplate of spring framework, it adds routing support for data access requests so that the applications can access multiple database partitions/shards transparently. Besides, CobarSqlMapClientTemplate also provides several additional functionalities to ease application development and monitoring. Now we will elaborate on functionalities of CobarSqlMapClientTemplate in the following sections.
Before database partitioning, the applications only need to provide a single data source dependency for SqlMapClientTemplate of spring framework, it seems like the following:
<bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> ... </bean>
After database partitioning, the data access requests might access multiple data partitions, that's, we now need a dependency of multiple data sources. We also need to find a way to manage these multiple data sources dependency, and inject these multiple data sources dependency to CobarSqlMapClientTemplate for use. In CobarClient, the “ICobarDataSourceService” abstraction will help to manage these multiple data sources dependency, the “ICobarDataSourceService” is defined as:
public interface ICobarDataSourceService {
Map<String, DataSource> getDataSources();
Set<CobarDataSourceDescriptor> getDataSourceDescriptors();
}
The “ICobarDataSourceService” will be responsible for providing a group of data sources as dependency of CobarSqlMapClientTemplate, even more, it can also provide meta information of each data source. “ICobarDataSourceService” has a default implementation, that's, com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService. With DefaultCobarDataSourceService, we can manage the data sources in a central way, and inject them into CobarSqlMapClientTemplate for use. A general configuration with CobarSqlMapClientTemplate and its “ICobarDataSourceService” dependency looks like:
<bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> ... </bean> <bean id="dataSources" class="com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService"> <property name="dataSourceDescriptors"> <set> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition1"/> <property name="targetDataSource" ref="partition1_main"/> <property name="targetDetectorDataSource" ref="partition1_main"/> <property name="standbyDataSource" ref="partition1_standby"/> <property name="standbyDetectorDataSource" ref="partition1_standby"/> <property name="poolSize" value="10"/> </bean> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition2"/> <property name="targetDataSource" ref="partition2_main"/> <property name="targetDetectorDataSource" ref="partition2_main"/> <property name="standbyDataSource" ref="partition2_standby"/> <property name="standbyDetectorDataSource" ref="partition2_standby"/> </bean> </set> </property> <property name="haDataSourceCreator"> <bean class="com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator"> <property name="detectingSql" value="update cobarha set timeflag=CURRENT_TIMESTAMP()"/> </bean> </property> </bean> <bean id="partition1_main" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> ... </bean> <bean id="partition1_standby" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> ... </bean> <bean id="partition2_main" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> ... </bean> <bean id="partition2_standby" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close"> ... </bean>
Note that, CobarSqlMapClientTemplate still needs a SqlMapClient of iBatis as dependency, because “CobarSqlMapClientTemplate is still a SqlMapClientTemplate ” (If SqlMapClientTemplate needs it, CobarSqlMapClientTemplate should need it too.). Attention should be paid to the configuration of “com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService ” , here we inject a group of com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor via “dataSourceDescriptors” attribute, while CobarDataSourceDescriptor is mainly responsible for providing descriptions of each data source, which contains the following configuraiton items:
identity. the identity of data partition, it can't collide with other partitions' identity value. When defining routing rules, it will be part of the rules.
targetDataSource. the main target data source, in genernal, this data source should be active when the application is gonna startup.
targetDetectorDataSource. the paired data source of “targetDataSource” which will be used to detect the healthy status of the target database. Both “targetDataSource” and “targetDetectorDataSource” should be pointed to a same database. But they should be configured independently so that they won't interfere with each other.(The above confiugration use same data source reference, this is only for demo, but in production environment, 2 independent datasources should be configured.)
standbyDataSource. The standby data source for “targetDataSource” , when “targetDataSource” is down, Cobarclient will automatically failover to this data source. (The prerequisite is the HA functionality is enabled in CobarClient.)
standbyDetectorDataSource. the paired data source of “standbyDataSource” which will be used to detect the healthy status of the target database. Refer to explanation of “targetDetectorDataSource” for more information.
poolSize. CobarSqlMapClientTemplate will use the value of “poolSize” as a hit to create corresponding thread pools. Since creating too many threads will cause performance penalty, usually we will create a thread pool for each data source executor with thread count that equals to “poolSize” , if “poolSize” is not given, a default value will be used, that's, “CPU numbers * 5” ;
Note
Currently, our internal applications all depend on data sources bound to JNDI, and CobarClient can't get enough information on data sources, and further can't create independent data source dependencies as per only one copy of data source configuration information. That's why we need to configure a paired data source to be used as detetion purpose. Of course, only HA functionality is enabled, otherwise, those paired data sources are optional.
In our configuration sample above, we use C3P0 data source implementation, but it's not the only option for CobarClient, CobarClient only depends on standard JDBC “DataSource” interface, So no matter what kind of data source implementations or where the data sources come from, CobarClient can do.
CobarDataSourceDescriptor currently only contains necessary information that specific to our internal database deployment structure, that's, it only tries to describe a horizontal scaled with 2-master-active nodes structure, but this structure may change, so CobarDataSourceDescriptor will chagne too as per speicific situations.
Tip
If HA functionality is not needed, then you can point both “standby(.*)DataSource” to their specific “target(.*)DataSource” , or just don't assign a value to the “haDataSourceCreator” attribute of DefaultCobarDataSourceService, then standbyDataSource,standbyDetectorDataSource and targetDetectorDataSource are not necessary to configure.
The data source references of CobarDataSourceDescriptor can be from JNDI, or from internal IoC Container(just as we do in the tests, we use C3P0 in spring container), even other types of data sources, as long as they conform to standard JDBC “DataSource” interface.
DefaultCobarDataSourceService not only depends on a group of CobarDataSourceDescriptor, but also depends on an “IHADataSourceCreator” to support HA of databases. If no “IHADataSourceCreator” is given, DefaultCobarDataSourceService will create a “NonHADataSourceCreator” to use as default, that's, don't create HA-enabled data sources. Of course, CobarClient also provides a default HA-enabled facility, that's, “FailoverHotSwapDataSourceCreator” , you can decide which one to use or provide the ones you implement by youself to meet your needs.
CobarClient supports failover between 2 active nodes, the failover functionality is abstracted and hidden under interface definition of IHADataSourceCreator:
public interface IHADataSourceCreator {
DataSource createHADataSource(CobarDataSourceDescriptor descriptor) throws Exception;
}
As we said before, DefaultCobarDataSourceService will depend on an “IHADataSourceCreator” to create data source instances that support hot-swap between 2 active nodes. com.alibaba.cobar.client.datasources.ha.NonHADataSourceCreator和com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator are the mostly used “IHADataSourceCreator” implementations, but NonHADataSourceCreator is mainly for tests scenarios or scenarios that don't need HA support(if database servers can handle HA concerns, then it's not necessary to enable HA support in CobarClient) and FailoverHotSwapDataSourceCreator is the one that we will use most of the time to enable HA support of CobarClient.
FailoverHotSwapDataSourceCreator can support two types of HA abilities: active detection HA and passive detection HA. They can be controlled by “passiveFailoverEnable” and “positiveFailoverEnable” attributes, at default, active detection HA is enabled, but passive detection HA is disabled, because as per the experiences from “Cobar(Server Edition)” , checking connection status frequently will cause performance penalty.
The active detection HA functionality follows the idea used in Cobar(Server Edition), it needs a table in target databases to use as update target, and the detector will send out update sql to the detection table periodically. Suppose we create a detection table named “cobarha” , then we can configure our FailoverHotSwapDataSourceCreator as follows:
<bean id="haDataSourceCreator" class="com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator"> <property name="detectingSql" value="update cobarha set timeflag=CURRENT_TIMESTAMP()"/> </bean>
FailoverHotSwapDataSourceCreator will send this SQL to target database periodically to detect the healthy status of it. If the timeout exceeds or exceptions are raised, and after specified retry times, then FailoverHotSwapDataSourceCreator will switch current target database to standby target database. The detection interval, timout, and retry times can be set via corresponding properties of FailoverHotSwapDataSourceCreator. Refer to the javadoc of FailoverHotSwapDataSourceCreator for more inforamtion.
Besides the dependency on some “ICobarDataSourceService” to manage multiple data sources, another important dependency of CobarSqlMapClientTemplate is an “ICobarRouter” which will be responsible for routing data access requests to their target data partitions/shards.
Here is the interface definition of ICobarRouter:
public interface ICobarRouter<T> {
RoutingResult doRoute(T routingFact) throws RoutingException;
}
As the inferface states, it can return a RoutingResult as per the context information passed in via routingFact argument.
Different implementations of “ICobarRouter” can be provided, for example, Cobar Client provides “com.alibaba.cobar.client.router.CobarClientInternalRouter ” and “com.alibaba.cobar.client.router.DefaultCobarClientInternalRouter ” as default ones, if too many routing rules available, to enhance the performance of routing rules search, some implementation can be done with Rete algorithm too. If no special requirements, usually we will use “CobarClientInternalRouter” as the default Router implementation used by CobarSqlMapClientTemplate, or use “DefaultCobarClientInternalRouter” as an alternative, which does some optimization on routing rule matching with groups, this trades complexity of configuration for simplicity and high performance at runtime. If there are too many routing rules, consider to use DefaultCobarClientInternalRouter for good.
Note
The configuration of DefaultCobarClientInternalRouter can be done with 2 FactoryBean helper: “com.alibaba.cobar.client.router.config.DefaultCobarClientInternalRouterXmlFactoryBean ” and “com.alibaba.cobar.client.router.config.StaticCobarClientInternalRouterFactoryBean ” , the former allows to define and load routing rules in xml configuration files, and the latter allows to define routing rules as bean definitions in spring ioc container directly. You can decide which one to use as per your scenarios. More information can be found in javadoc and further explanation on “CobarClientInternalRouter” in next content.
Since CobarSqlMapClientTemplate is mainly for iBatis, the routing fact type of CobarClientInternalRouter is called “IBatisRoutingFact” which is listed below:
public class IBatisRoutingFact {
// SQL identity
private String action;
// the argument of SQL action
private Object argument;
// ...
}
It says, CobarClientInternalRouter will route as per 2 parts of information, one is the sqlmap id in ibatis's sqlmap, the other is the argument object of data access method. CobarClientInternalRouter will evaluate the passed-in IBatisRoutingFact context object against one or more groups of routing rules, and return the matched result. After that, CobarClientInternalRouter will know where or which node(s) to route the data access requests.
In general, CobarClientInternalRouter can accept 4 types of routing rules, but it's usually not necessary for general users to know exactly what these types are. In order to prevent these users from involving too much with the implementation details of CobarClientInternalRouter, we provide a FactoryBean helper to simplify the configuration of CobarClientInternalRouter, this FactoryBean is “com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean ” , here is a simple sample on how to use it:
<bean id="internalRouter" class="com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean"> <property name="configLocation" value="classpath:META-INF/rules.xml" /> </bean>
CobarInteralRouterXmlFactoryBean will read xml-format configuration file and assemble different types of routing rules as per the read content, then inject the assembled routing rules into CobarClientInternalRouter instance. CobarInteralRouterXmlFactoryBean will hide trivial things like read configuration, parse configuration , assemble different types of rule instances,etc. All of these trivial things are transparent to the final users. But, no matter how hard we try to hide these things, the final users still need to provide essential things, for example, the content of the configuration. Only when users provide correctly configured routing rules as per applications' scenarios, CobarClientInternalRouter can work correctly. So in the next section, we will explain more details on how to define routing rules.
Tip
You can give a single configuration location by “configLocation” property, you can also give a group of configuration file locations via “configLocations” , the latter way helps on modular parallel development.
Note
Although we recommand to use CobarInteralRouterXmlFactoryBean to configure the CobarClientInternalRouter instance but if needed, we can also give out other types of FactoryBean helpers, like the ones use DSL, or based on Excel. As long as we indeed need them, they can be done by extending the basc facilities.
A simple sample configuration file for routing rules looks like:
<rules>
<rule>
<namespace></namespace>
<sqlmap></sqlmap>
<shardingExpression></shardingExpression>
<shards></shards>
</rule>
</rules>
<rules> element has more <rule> elements, while <rule> element has 4 more sub-elements:
namespace or sqlmap. The only difference between them is the granularity on definiting routing rules. That's, “sqlmap” represents the statement id in some iBatis SqlMap configuration file; while “namespace” is mapped to the namespace of some iBatis SqlMap configuraiton file. The 2 elements are excluded with each other, when defining routing rules, only one element of them can be chosen to be defined under “<rule>” element, otherwise, CobarInteralRouterXmlFactoryBean will throw configuraton exception at startup.
shardingExpression. The value of this element is expressions of MVEL format, it will be evalued against dynamic context information, usually the argument of data access methods.
shards. partition/shards ids which is deemed as routing result, they should be the “identity” values of “CobarDataSourceDescriptor” s. If more partition/shards involves when routing rules match, one or more partition/shard ids can be given here.
The definition of rule can be simplified into format of “condition->action” , that's, “(namespace | sqlamp) + shardingExpression -> shards” .
As we see the rule definition is so simple, so it's not mandatory to use DTD or XML schema to validate against the xml configuration files, but if you would like to, the following DTD definition can be used:
<?xml version="1.0"? encoding="UTF-8"?> <!ELEMENT rules (rule)+> <!ELEMENT rule ((namespace|sqlmap),shardingExpression,shards)> <!ELEMENT namespace (#PCDATA)> <!ELEMENT sqlmap (#PCDATA)> <!ELEMENT shardingExpression (#PCDATA)> <!ELEMENT shards (#PCDATA)>
With above theory of routing rules, in the next section, we will explain how to define routing rules as per the scenarios of the applications.
Note
CobarClient use MVEL to evaluate against “shardingExpression” 's value, so the users have to make sure the value of “shardingExpression” should conform to MVEL syntax. You can find docuement on MVEL here .
The routing rules seem simple, but before explaining more details about them, maybe you can figure out how to define them, how to use them, even why they should be defined in this way. So now we will explain the details of routing rules for you.
To do data access with iBatis, we need to define a SqlMap configuration file, like this:
<?xml version="1.0" encoding="GB2312"?>
<!DOCTYPE sqlMap PUBLIC "-//iBATIS.com//DTD SQL Map 2.0//EN" "http://www.ibatis.com/dtd/sql-map-2.dtd">
<sqlMap namespace="com.alibaba.cobar.client.entities.Offer">
<typeAlias alias="offer" type="com.alibaba.cobar.client.entities.Offer" />
<resultMap id="offer" class="offer">
<result property="id" column="id" />
<result property="memberId" column="memberId" />
<result property="subject" column="subject" />
<result property="gmtUpdated" column="gmtUpdated" />
</resultMap>
<insert id="create">
INSERT INTO offers(memberId, subject, gmtUpdated) VALUES(#memberId#, #subject#, #gmtUpdated#)
<selectKey keyProperty="id" resultClass="long">
SELECT LAST_INSERT_ID();
</selectKey>
</insert>
...
</sqlMap>
As we see, each SqlMap has a “namespace” , and under each namespace, you can define more sql statements, each sql statement has an “id” as its identity. The “namespace” plus “id” of statement can identify each sql statement in global scope. With this prerequisite, let's see how to define the routing rules as per ibatis SqlMap configuration.
Let's start from special scenarios to general ones.
Take the “create” statement as example, Suppose we have an “offer” table and its data is splitted into 2 databases. The partition strategy is: The records with odd memberId will be stored on partition1, while the records with even memberId will be stored on partition2. To route the data access requests on “offer” table, the simple way is to check which sql statement the data access request uses and whether the memberId of the record is odd or not. So 2 routing rules can be defined as:
<rules>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shardingExpression>memberId % 2 == 1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shardingExpression>memberId % 2 == 0</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
<sqlmap> element is equal to the sql statement identity, usually the fully qualified name with both “namespace” and “sql statement id” involved. <shardingExpression> defines the sharding expression as per our original partition strategy. At last, <shards> return the final routing result. Until now, I think you should have basic knowledge on how to define the routing rules in CobarClient.
With above basic knowledge, let's change our scenario. We still perform “create” operation, but this time we use vertial parition strategy instead of horizontal partition strategy. That's, all of the “offer” table records will be stored on a same database, now we change our routing rule definitions as below:
<rules>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shardingExpression>memberId % 2 == 1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shardingExpression>memberId % 2 == 0</shardingExpression>
<shards>partition1</shards>
</rule>
</rules>
As the rule definitions state, no matter the memberId is odd or even, the records will all be stored on “partition1” . But it's stupid to have duplication things here. We can simplify the routing rule definition as below:
<rules>
<rule>
<sqlmap>com.alibaba.cobar.client.entities.Offer.create</sqlmap>
<shards>partition1</shards>
</rule>
</rules>
That's, only a single <sqlmap> element can do here, no shardingExpression element is needed. The rule reads in this way - “As long as I find the sqlmap value is com.alibaba.cobar.client.entities.Offer.create, I will route data access requests to partition1, no matter the memberId of the record is odd or even.”
We call the first style of routing rule as SqlActionShardingRule , while call the 2nd style of routing rule as SqlAction(Only)Rule , They are routing rules to be used under horizontal partition strategy and vertial partition strategy.
Let's further extend the scenarios, obviously, we need to provde update or delete operations for offer table, besides create opertion. So we add more sql statements into SqlMap configuration file as below:
<?xml version="1.0" encoding="GB2312"?>
<!DOCTYPE sqlMap PUBLIC "-//iBATIS.com//DTD SQL Map 2.0//EN" "http://www.ibatis.com/dtd/sql-map-2.dtd">
<sqlMap namespace="com.alibaba.cobar.client.entities.Offer">
<typeAlias alias="offer" type="com.alibaba.cobar.client.entities.Offer" />
<resultMap id="offer" class="offer">
<result property="id" column="id" />
<result property="memberId" column="memberId" />
<result property="subject" column="subject" />
<result property="gmtUpdated" column="gmtUpdated" />
</resultMap>
<insert id="create">
INSERT INTO offers(memberId, subject, gmtUpdated) VALUES(#memberId#, #subject#, #gmtUpdated#)
<selectKey keyProperty="id" resultClass="long">
SELECT LAST_INSERT_ID();
</selectKey>
</insert>
<update id="update">
UPDATE offers SET subject=#subject#, gmtUpdated=#gmtUpdated# WHERE id=#id#
</update>
<delete id="delete">
delete from offers where id=#id#
</delete>
...
</sqlMap>
With only supports of SqlActionShardingRule and SqlAction(Only)Rule , to make the update and delete operations to be routed to correct target databases, we have to add more and more routing rules in our rule configuration files, the problems with this are:
Whenever adding a new SqlMap configuration file, a collection of routing rules have to be defined for a series of CRUD operations, that will be too much ado.
In vertical partition scenarios, usually on matter what kinds of data access methods we use, the data access requests to a same table will be routed to a same data partition/shard,that's, one routing rule can suffice for all of the data access requests onto one table.
So to improve or fix these problems mentioned above, we introduce two new routing rule types: “NamespaceShardingRule” and “Namespace(Only)Rule” .
NamespaceShardingRule allows us to define routing rules as per namespace in a SqlMap and horizontal sharding strategy. Still take original partition scenario as an example, that's, records with odd memberId will be stored on partition1, and records with even memberId will be stored on partition2. With NamespaceShardingRule, no matter what kinds of opertations are used(update or create), as long as the sql statements are defined under a same namespace(the namespace is com.alibaba.cobar.client.entities.Offer for our scenario), and the context object conforms to the sharding strategy, we can define one single routing rule of kind of NamespaceShardingRule to route the data access requests corretly, a sample such routing rules definition is listed below:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>memberId % 2 == 1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>memberId % 2 == 0</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
With NamespaceShardingRule, we don't need to define every routing rules as per each data access sql statements. It helps save lot of repeated works on defining almost same routing rules. Further, if all of the data of a table is stored in a same partition(vertical partition scenarios), then we can use a Namespace(Only)Rule to save more configuraton works, a sample Namespace(Only)Rule defintion is listed below:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shards>partition1</shards>
</rule>
</rules>
With only this rule, all of the sql statements under namespace “com.alibaba.cobar.client.entities.Offer” will be routed to partition1. .
In conclusion, from SqlActionShardingRule, SqlAction(Only)Rule to NamespaceShardingRule and Namespace(Only)Rule, the routing rule defintions will cover the routing scope from specific to generic ones. If some sql statement needs a special routing requirement, then we can add a SqlActionShardingRule or SqlAction(Only)Rule to meet the need; while if multiple sql statments have similar or same routing requirements, then we can add some NamespaceShardingRule or Namespace(Only)Rule to complete the requests. Anyway, you can use all of the four routing rule types by composition or using them independently to achieve all of the data access routing requirements with iBatis.
Tip
When defining the routing rules, we can start from generic scenarios with NamespaceShardingRule or Namespace(Only)Rule, then add SqlActionShardingRule or SqlAction(Only)Rule for special scenarios. CobarClientInternalRouter internally will choose to use special scenarios' routing rules firstly, if no such routing rules are found, it will choose to use generic scenarios' routing rules as fallback.
Common horizontal partition strategies/algorithm may be:
Range-based partition, e.g. “memberId > 10000 and memberId < 20000”
Mod-based partition(or round-robin partition), e.g. “memberId%128==1” or “>memberId%128==2” or ...
Hash-based partition, for example, “hashing(memberId)==someValue” .
There are also other partition strategies, like “predicate-based partition” ,etc. In order to meet the needs of different partition strategies, we CobarClient allows to define custom functions in the “shardingExpression” when defining routing rules.
Here follows a simple sample about how to define custom routing functions in CobarClient.
Suppose we will apply some hashing algorithm on memberId, and route the records as per the hashing result of their memberId. Firstly, we need to define a function class which will return a hashing result as per the memberId argument we pass in, we define the function class as below:
public class Hashing{
...
int apply(Long memberId){
// perform real logic here.
}
}
In order to use this function in “shardingExpression” , we need to register it first. We register custom functions via “functionsMap” property of CobarInteralRouterXmlFactoryBean:
<bean id="internalRouter" class="com.alibaba.cobar.client.router.config.CobarInteralRouterXmlFactoryBean"> <property name="functionsMap"> <map> <entry key="hash"> <bean class="..Hashing"> </bean> </entry> </map> </property> <property name="configLocations"> <list> <value>classpath:META-INF/routing/offer-sql-action-rules.xml</value> <value>classpath:META-INF/routing/offer-sharding-rules-on-namespace.xml</value> </list> </property> </bean>
Pay attention to the key value of our custom function, here it is “hash” .
With all of the above things done, we now can use our custom function in “shardingExpression” , just as the sample below:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>hash.apply(memberId) == someValue</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>hash.apply(memberId) == anotherValue</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
As we can see, the custom function is invoked by the reference of former registered key value, “hash” , you can apply any function methods to the partition context object as long as you have defined those function methods. Easy to understand, right?
CobarSqlMapClientTemplate provides an extension point on auditing and analyzing SQL, but no available implementations are given, since ICBU of Alibaba has something of their own to do the same thing. But if you do need such a feature/functionality, you can gain it by injecting an “ISqlAuditor” implementation to CobarSqlMapClientTemplate.
The interface definition of ISqlAuditor is simple:
public interface ISqlAuditor {
void audit(String id, String sql, Object sqlContext);
}
you can get anything necessary to do SQL auditing by method arguments. The “id” is the value of sqlmap statement's id in iBatis; Argument “sql” is the sql statement you want to audit, but if current ibatis statement is a DynamicSQL, the value of this argument will be null; Last, the Argument “sqlContext” will be the argument object of data access methods. Your applications can decide how to implement and use your own “ISqlAuditor” implementations. In order to prevent performance penalty when doing sql auditing, the implementations of your own “ISqlAuditor” should make it run in asynchronous way so that it will not block other data access requests execution. Of course, we have further checks this point.
When you inject an “ISqlAuditor” for CobarSqlMapClientTemplate, it will check whether you have injected a paired ExecutorSerivce for your “ISqlAuditor” , If no such ExecutorSerivce is provided with your “ISqlAuditor” , CobarSqlMapClientTemplate will create one, with only 1 worker thread. But if you do want to get dirty with this, you can provide your own ExecutorSerivce by injecting via sqlAuditorExecutor property of CobarSqlMapClientTemplate. If so, you also should remember to clean up your own ExecutorService too. This trick is mainly for bad “ISqlAuditor” implementations in case they slow down the whole execution process.
For application monitoring, we provide a long-run-sql-logging functionality for CobarSqlMapClientTemplate, this functionality is not enabled automatically, if you want to enable it, set profileLongTimeRunningSql property's value to true, furthermore, you need to set a time threshold via longTimeRunningSqlIntervalThreshold property, if the value of it is less or equal to zero, exception will be thrown to prevent to initialize a wrong-state CobarSqlMapClientTemplate instance.
Here is a configuration sample snippet:
<bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> ... <property name="profileLongTimeRunningSql" value="true" /> <property name="longTimeRunningSqlIntervalThreshold" value="3600000" /> </bean>
If you applications depend on MySQL as data storage, then probably you will use bulk insert to insert a batch of data with sql like “INSERT INTO tab(..) VALUES(..), (..), (..), (..)...” . To support this, you can submit a BatchInsertTask to CobarSqlMapClientTemplate, CobarSqlMapClientTemplate will check the type of method arugment, if it finds the type is of BatchInsertTask, it will resort and classify the collection of data as per the routing rules, then submit to execution queues of each target data sources and execute them in parallel.
This functionality can save the applications to resort and classify the data by themselves, meantime, the routing rules can be used too to route the data flow to their target data sources.
Now, suppose we have a data object below:
public class Offer {
private Long id;
private Long memberId;
private String subject;
private Date gmtUpdated = new Date();
// setters and getters and other method definitions
}
and we have the following routing rules defined:
<rules>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>memberId < 10000</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>com.alibaba.cobar.client.entities.Offer</namespace>
<shardingExpression>memberId > 10000 and memberId < 20000</shardingExpression>
<shards>partition2</shards>
</rule>
</rules>
When we submit a batch of Offer records to CobarSqlMapClientTemplate by BatchInsertTask, the records will be classified as per the routing rules, and bulk insert into the target data sources.
Note
we can even make the routing rules more specific by changing to use SqlActionShardingRules instead of NamespaceShardingRules we used above.
The ability of query result mergence in CobarClient is weak(so is Cobar server edition)), the mergence behavior is only adding result records to a List and return, that means, the applications have to decide how to retrieve the result object as per their usage scenarios. For example, if we execute such a SQL below:
select count(*), companyId from offer group by companyId
If the routing rule for this SQL returns multiple target data sources, then this SQL will be executed on these data sources and the results will be returned independently. If we add all of the results into a List, then the List will contain multiple tuples of “(Count, companyId)” , a same companyId will contain in multiple records, the applications may need to sum up all of the result records by themselves.
Currently, CobarClient apply the same strategy to all of the query results, so the applications should pay attention to the impact this strategy bring to them. In the future, CobarClient will improve the data mergence strategy and allows the applications to control the mergence behavior by providing their own mergence strategies.
If you execute a query SQL with orderby condition with the queryForList() method of CobarSqlMapClientTemplate, the results returned may be not the one you expect, since the default mergence strategy may not help, the order of query result is not guaranteed. But if we want to reuse these ordered result sets and return a final sorted result object, CobarSqlMapClientTemplate does can help on this scenario. The idea is similar to the merge-sort algorithm, that's, the databases help on the latter sort part, and we CobarClient does the former “merge” part.
To use custom mergence strategies, we have to set a group of the mappings between SqlMapActionId and custom mergence strategy implementation via the “mergers” property of CobarSqlMapClientTemplate, here is an example:
<bean id="sqlMapClientTemplateWithMerger" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> <property name="router" ref="internalRouter" /> <property name="sqlAuditor"> <bean class="com.alibaba.cobar.client.audit.SimpleSqlAuditor" /> </property> <property name="profileLongTimeRunningSql" value="true" /> <property name="longTimeRunningSqlIntervalThreshold" value="3600000" /> <property name="mergers"> <map> <entry key="com.alibaba.cobar.client.entities.Offer.findAllWithOrderByOnSubject" value-ref="merger" /> </map> </property> </bean> <bean id="merger" class="com.alibaba.cobar.client.merger.ConcurrentSortMerger"> <property name="comparator" ref="comparator"> </property> </bean> <bean id="comparator" class="com.alibaba.cobar.client.support.OfferComparator"> </bean>
As the configuration says, all of the query results returned from the execution of “com.alibaba.cobar.client.entities.Offer.findAllWithOrderByOnSubject ” will be merged by using the “merger” we defined. The “merger” we use is an implementation of interface “IMerger” , that's, com.alibaba.cobar.client.merger.ConcurrentSortMerger. Most of the times, ConcurrentSortMerger can suffice our needs, What we need to do is providing a Comparator for it as per the attributes of query results. But if it can do, we can define our own “IMerger” implementations.
Note
In fact, this may look messy, because the order-by information can be analyzed the SQL of SqlMapActionId, but currently we would like to just provide the simple mergence functionality instead of introducing more complexity. Furthermore, if it's a DynamicSql, we can't get the definite SQL from the application layer, then it also means the latter solution can't help everything from the application layer.
If needed, the later versions of CobarClient can provide result set mergence ability by analyzing SQL.
As per requirements from ICBU internal, CobarClient needs to guarantee local transactions of multiple databases, and distributed transaction is not acceptable, because the latter will involve unnecessary performance problems. With such a prerequisite, we choose to implement Cobarclient's transaction support by using “Best Efforts 1PC Pattern” [2] .
CobarClient provides a custom TransactionManager - MultipleDataSourcesTransactionManager to support “Best Efforts 1PC Pattern” transaction management. MultipleDataSourcesTransactionManager accepts a group of data sources as target transaction resources, when the transaction is started, all of the local transactions on these data sources will be started too; when the transaction is committed or rolled back, then all of the local transactions will be committed or rolled back. When starting local transactions on all of the data sources, a physical connection will be occupied, this may cause performance problems, so we intercept all of the data sources and wrap them with LazyConnectionDataSourceProxy, this proxy will guarantee that only when at least one data access operation occur, the physical connection should be fetched. MultipleDataSourcesTransactionManager and LazyConnectionDataSourceProxy facilities are marked in previous architecture graphic as (1) and (2).
In fact, to prevent from occupying too many physical connections, we have another way. We can explicitly define which data sources should join the transaction by Annotation in service layer or external configuration, then unnecessary connections will not be fetched. But someone deems this strategy intrude too much on service layer, so for the time being, we just use MultipleDataSourcesTransactionManager plus LazyConnectionDataSourceProxy to complete transaction management with “Best Efforts 1 PC Pattern” .
To make sure the transaction are targeted upon a same group of data sources, we need to inject MultipleDataSourcesTransactionManager the same group of data sources as CobarSqlMapClientTemplate has. This is done by still using “ICobarDataSourceService” abstraction:
<bean id="transactionManager" class="com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager"> <property name="cobarDataSourceService" ref="dataSources" /> </bean> <bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient" /> <property name="cobarDataSourceService" ref="dataSources" /> ... </bean> <bean id="dataSources" class="com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService"> <property name="dataSourceDescriptors"> <set> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition1"/> <property name="targetDataSource" ref="partition1_main"/> <property name="targetDetectorDataSource" ref="partition1_main"/> <property name="standbyDataSource" ref="partition1_standby"/> <property name="standbyDetectorDataSource" ref="partition1_standby"/> </bean> <bean class="com.alibaba.cobar.client.datasources.CobarDataSourceDescriptor"> <property name="identity" value="partition2"/> <property name="targetDataSource" ref="partition2_main"/> <property name="targetDetectorDataSource" ref="partition2_main"/> <property name="standbyDataSource" ref="partition2_standby"/> <property name="standbyDetectorDataSource" ref="partition2_standby"/> </bean> </set> </property> <property name="haDataSourceCreator"> <bean class="com.alibaba.cobar.client.datasources.ha.FailoverHotSwapDataSourceCreator"> <property name="detectingSql" value="update cobarha set timeflag=CURRENT_TIMESTAMP()"/> </bean> </property> </bean> ...
So that's it, easy as pie to use MultipleDataSourcesTransactionManager, right?
Note
Refer to section “Multiple DataSources Management” for more information on com.alibaba.cobar.client.datasources.DefaultCobarDataSourceService. More configuration details about MultipleDataSourcesTransactionManager can be found in the javadoc of it or the javadoc of AbstractPlatformTransactionManager in spring framework.
We hope CobarClient can provide an abstraction layer to hide the complexity of distributed data access, also minimize the efforts to access multiple different data storage services.
We also hope to provide a consistent data access layer which can standardize the data access behaviors of the applications, and as the requirements and architecture evolve, more functionalities can be introduced into this layer, including data replication and synchronization, data caching, real-time index building, etc. With this CobarClient, the applications only need to know the concerns they are real care about, rather to care about what changes, how much changes, the left things can leave to CobarClient to take care of.